I need to remove some white spaces between specific characters only. This is my data:
#1 2 5 1#
# 5 5 3#: 100% #5 55#
#554 #: 23
#559#: 30%
#4 79#: 2 0 0#%
#473#: 20 #47 4#
#4 7 4 43 33 5 5#: 15s
#4 79#: 195%
#473#: 20 # 474#
#475#: 14.5s
I want all of the whitespaces between two # # tags, that are not separated by anything other than numbers, removed. My data should look like this:
#1251#
#553#: 100% #555#
#554#: 23
#559#: 30%
#479#: 2 0 0#%
#473#: 20 #474#
#474433355#: 15s
#479#: 195%
#473#: 20 #474#
#475#: 14.5s
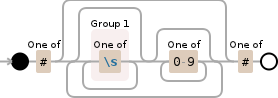
I'm currently trying to use the following regex in PHP to preg_replace those whitespaces, however, everything I've tried was unsuccessful.
(?:[#])(?:([\s])*[0-9]*)*(?:[#])