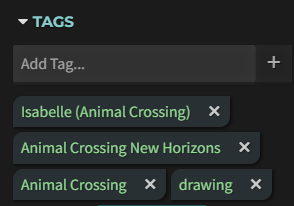

比如说我想爬取这4个标签(这只是我要爬取的其中一个网页)
这是我的部分代码:
spider.py
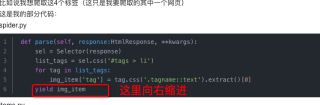
def parse(self, response:HtmlResponse, **kwargs):
sel = Selector(response)
list_tags = sel.css('#tags > li')
img_item = ProjectItem()
img_item['image_path'] = sel.css('img#wallpaper::attr(src)').extract()[0]
for tag in list_tags:
img_item['tag'] = tag.css('.tagname::text').extract()[0]
yield img_item
items.py
class ProjectItem(scrapy.Item):
image_path = scrapy.Field()
tag = scrapy.Field()
在终端输入 scrapy crawl wallhaven -o data.csv 之后,生成的csv文件每个image_path都只对应一个标签,并没有4个,请问该如何修改代码,能让这4个标签都显示在一行?