以下这一段,是我进行新闻汽车之家爬取时,需要构建网页,步长为10,即第一页是0,第二页是10,第三页是20,以此类推。我执行以下代码是获取了第一位i,即0,获取了第一页的网址。但是第二页,第三页获取不了 这是为什么啊
import requests
from bs4 import BeautifulSoup
urls=[]
for i in range(0,4,10):
url="https://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=%E6%96%B0%E9%97%BB%E6%B1%BD%E8%BD%A6%E4%B9%8B%E5%AE%B6&cl=2&x_bfe_rqs=032000000000000000000000000000000000000000000008&x_bfe_tjscore=0.080000&tngroupname=organic_news&newVideo=12&goods_entry_switch=1&rsv_dl=news_b_pn&pn={}%22.format(i)
urls.append(url)
print(urls)

爬虫构建网页 获取不了多个网页

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
 [小G] 2022-10-23 18:52关注
[小G] 2022-10-23 18:52关注range(0,41,10)分别得到0,10,20,30,40
range三个参数意思分别是:start开始,end结束,step步长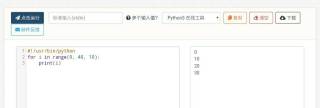 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
- 2022-10-23 18:36回答 1 已采纳 range(0,41,10)分别得到0,10,20,30,40range三个参数意思分别是:start开始,end结束,step步长
- 2022-05-12 14:48回答 2 已采纳 这代码里面好多错误,你是怎么运行成功的?
- 2022-09-24 23:49回答 1 已采纳 http协议都没加
- 2023-09-19 00:41海拥✘的博客 Python是一个流行的编程语言,具有丰富的库和框架,使得构建和运行网络爬虫变得相对容易。本文将深入探讨如何使用Python构建一个简单的网络爬虫,以从网页中提取信息。网络爬虫是一项强大的技术,可用于从互联网上的...
- 2021-07-30 00:11回答 4 已采纳 对你有帮助的话,建议采纳。
- 2022-04-05 22:09回答 3 已采纳 因为 个别标签字典中没有bond_nm和bond_nm_tip键 data2 = data_get['bond_nm'] data5 = data_get['bond_nm_tip']
- 2022-06-24 19:43回答 1 已采纳 其实有的,但是这个网站应该是为了懒加载把url用base64密了一下,然后再动态加载, 其实我下面发的这个就是url 是base64后的url 解码后就是https://s1.aigei.com/
- 2021-07-19 17:55bestproxyreviews的博客 现在就一起来阅读我们关于如何构建一个简单的网络爬虫的文章。 您有没有想过程序员如何构建用于从网站中提取数据的网络抓取工具?如果你有,那么这篇文章就是专门为你写的。我们生活在一个数据驱动的世界已经...
- 2022-10-26 16:35回答 1 已采纳 post和get方法的使用不是你决定的,二十接口使用的是什么请求方式,如果它是get请求那就只能用get请求,是post就只能用post
- 2022-02-13 21:26回答 2 已采纳 寻找200多个链接的规律呀,先爬取200多个链接放到列表里,然后便历链接列表对每个链接发请求就行
- 2022-01-20 16:42回答 2 已采纳 我JAVA的.你说的应该是request请求里面.既有URL.又有参数等,JAVA这边有个深拷贝和浅拷贝.深拷贝可以达成.python这边你看下
- 2021-02-22 13:52程序IT圈的博客 阅读本文大约需要15~20分钟。本文章内容较多,非常干货!如果手机阅读体验不好,建议先收藏后到 PC 端阅读。之前做爬虫时,在公司设计开发了一个通用的垂直爬虫平台,后来在公司做了内部的技...
- 2021-10-31 23:19回答 1 已采纳 beautifulsoup是爬静态网页的,应该是有些内容属于动态,可以尝试selenium
- 2019-12-28 14:36Python新世界的博客 用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情。 我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存中,这个...
- 2022-04-13 09:00高成珍的博客 网络爬虫是一种程序,它的主要目的是将互联网上的网页下载到本地并提取出相关数据。网络爬虫可以自动化的浏览网络中的信息,然后根据我们制定的规则下载和提取信息。
- 没有解决我的问题, 去提问


问题事件
 系统已结题
10月31日
系统已结题
10月31日 已采纳回答
10月23日
已采纳回答
10月23日-
修改了问题
10月23日
-
创建了问题
10月23日
悬赏问题
- ¥15 FLUENT如何实现在堆积颗粒的上表面加载高斯热源
- ¥30 截图中的mathematics程序转换成matlab
- ¥15 动力学代码报错,维度不匹配
- ¥15 Power query添加列问题
- ¥50 Kubernetes&Fission&Eleasticsearch
- ¥15 報錯:Person is not mapped,如何解決?
- ¥15 c++头文件不能识别CDialog
- ¥15 Excel发现不可读取的内容
- ¥15 关于#stm32#的问题:CANOpen的PDO同步传输问题
- ¥20 yolov5自定义Prune报错,如何解决?