Python 0基础,工作原因需要进行大量数据处理,问题如下:
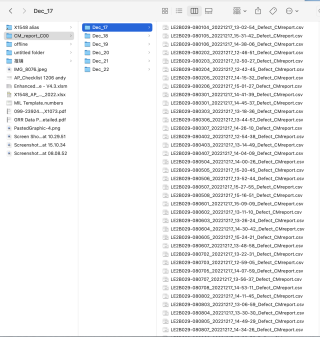
有以下路径:desktop/CM_report_C00/ 下多个sub folders, 每个sub- folder 有若干csv 文件,每个csv 文件内容如下图所示:
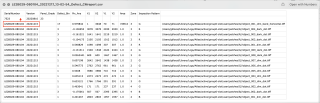
需要实现3个目标:
- 遍历所有子文件夹,统计csv 文件名中前14位出现的频次,例如 LE2B029-080104 出现1次,生成report.csv文件记录,此处并非遍历csv 内部内容的serial Number 出现的次数,只是看csv 文件名的前14位,确认是否有的产品测试了两次。
- 遍历所有csv 文件,将每个csv 的第三行前两列写入第二行前两列,无需生成新文件,在原文件做覆盖修改即可。
- 将第二步修改后的所有子文件夹的csv 文件merge 成一个allinone.csv,因原文件headname 最后一列缺失,增加最后一列的headname 为“path”
略附悬赏,望帮助
需注意的是,原文件的所有csv 文件,均如下图所示,最后一列没有head name,我之前尝试使用pandas 的时候会报错
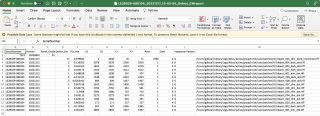
引用ShowmeAI 的答案,报错如下: