

提问仅用于科研学习,不涉及任何商业用途
通过网页打开准备获取的信息
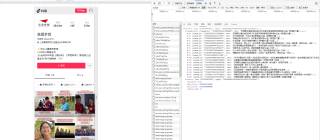
找到该内容的URL,并确定URL对应的就是上述内容:
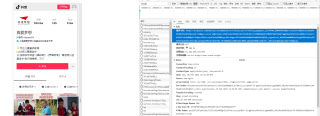
对应python代码如下:
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 '
'Safari/538.36 Edg/109.0.1516.67 '
}
url = 'https://m.douyin.com/web/api/v2/aweme/post/?reflow_source=reflow_page&sec_uid' \
'=MS4wLjABAAAAF6DBprxchsasOrovWpV5cSeLw1aKKfX1ONlSV5sDExI&count=21&max_cursor=0&msToken' \
'=VTpFKsbuCK5bmTK3ohT4iZRnbjJ7LtPQm9hQaVKCnHBVHr098t5hkXt3ggC86y49EqZ3S4uj4MXRsfIsSqsCJK6EhEC' \
'v8s8aRNQoCtJCQ4prS3DyFczfpoE3b1h9SMBALgc=&X-Bogus=DFSzKwVO5UUANGU6ShWhRKXAIQ53&_signature=_02B4Z6wo00001h' \
'uhShgAAIDDeKuKcq8UKXYbsU6AAOUZ7AI4sVgClohIqXJ2MfChE3TUAF1GJ.9FZKNW4OblnAHBtqmfIIMRB-wD6oW5U05NCkE3QrFFc.' \
'JBDlJOIFgmhsQl5cMarV7Hg0xza1 '
res = requests.get(url=url, headers=headers)
print('content', res.content)
print('text', res.text)
运行结果:
content b''
text
拟获取的信息理应是图一中右侧的信息,想请教一下是代码的问题吗,如何正确获取图一右侧内容?图一右侧的代码是json格式吗?







