本人再利用Jaccard计算文本相似度,希望代码可以遍历文件夹中每一篇文章,即得到每一文章与参考文档的相似度,但在遍历文件夹出现问题
import jieba
import jieba.posseg as psg
import codecs
#将不用拆分的词组载入jieba
jieba.load_userdict("D:\IEdownload\毕设\代码\非拆分.txt")
#定义转化为字符串函数
def standardization(filename):
data=''
with open(filename,'r',encoding='utf-8') as f:
for line in f.readlines():
line=line.strip('\n')
data+=line
return data
#定义jaccard相似度函数
def Jaccard(model,reference):
terms_reference=jieba.cut(reference)
terms_model=jieba.cut(model)
grams_reference=set(terms_reference)
grams_model=set(terms_model)
temp=0
for i in grams_reference:
if i in grams_model:
temp=temp+1
fenmu=len(grams_model)+len(grams_reference)-temp
jaccard_coefficient=float(temp/fenmu)
return jaccard_coefficient
#输入参照文档
query="D:\IEdownload\毕设\代码\参考文档.txt"
以下是我目前尝试的 目标文档遍历方法
import os
import re
path = "D:\IEdownload\毕设\新闻数据\保险集团\中国人寿1" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
for file in files: #遍历文件夹
position = path+'\\'+ file #构造绝对路径
with open(position, "r",encoding='gb18030') as f: #打开文件
data = f.read() #读取文件
#print("--------------------------")
#print(data)
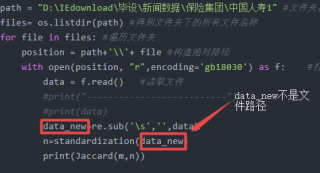
data_new=re.sub('\s','',data)
n=standardization(data_new)
print(Jaccard(m,n))
谢谢!!