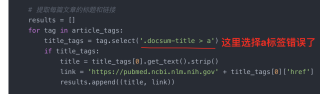
我做一个爬取pubmed的爬虫来爬取文章标题和链接。
可是能正常运行但是怕去不了数据,我测试后他说未发现文章。可是我用之前的一个用过的爬虫爬取同样的网站,他能爬取出文章,这是为什么啊各位。
这个是运行但不出数据
import requests
from bs4 import BeautifulSoup
url = 'https://pubmed.ncbi.nlm.nih.gov/?term=cervical%20cancer%20treatment&filter=years.2020-2023'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
def get_articles(url):
# 发送HTTP请求,获取页面数据
response = requests.get(url, headers=headers)
html = response.text
# 解析HTML代码
soup = BeautifulSoup(html, 'html.parser')
# 找到包含文章信息的标签
article_tags = soup.select('.docsum-content')
# 提取每篇文章的标题和链接
results = []
for tag in article_tags:
title_tags = tag.select('.docsum-title > a')
if title_tags:
title = title_tags[0].get_text().strip()
link = 'https://pubmed.ncbi.nlm.nih.gov' + title_tags[0]['href']
results.append((title, link))
return results
if __name__ == '__main__':
for page in range(1, 6):
page_url = f'{url}&page={page}'
articles = get_articles(page_url)
for article in articles:
print(article[0])
print(article[1])
print('---')
if __name__ == '__main__':
for page in range(1, 6):
page_url = f'{url}&page={page}'
articles = get_articles(page_url)
print(f'Page {page}: {page_url} ({len(articles)} articles found)')
for article in articles:
print(article[0])
print(article[1])
print('---')
这是可以运行的代码
```python
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://pubmed.ncbi.nlm.nih.gov/?term=cervical%20cancer%20treatment&filter=years.2020-2023"
num_pages = 10
data = []
for i in range(num_pages):
# Construct the URL for the current page
page_url = f"{url}&page={i+1}"
# Make a request to the page and parse the HTML using Beautiful Soup
response = requests.get(page_url)
soup = BeautifulSoup(response.content, 'html.parser')
# Find all the articles on the current page
articles = soup.find_all("div", class_="docsum-content")
# Extract the title and link for each article and append to the data list
for article in articles:
title = article.find("a", class_="docsum-title").text.strip()
link = article.find("a", class_="docsum-title")["href"]
data.append([title, link])
df = pd.DataFrame(data, columns=["Title", "Link"])
df.to_excel("cervical_cancer_treatment.xlsx", index=False)
```