
#描述遇到的问题
最近在用 pdfplumber 解析PDF数据时遇到解析表格不全的问题
代码
import pandas as pd
import pdfplumber
import re
import PyPDF2
path=r'./新版征信PDF.pdf'
coding='utf-8'
def extract_content(pdf_path):
# 内容提取,使用 pdfplumber 打开 PDF,用于提取文本
with pdfplumber.open(pdf_path) as pdf_file:
# 使用 PyPDF2 打开 PDF 用于提取图片
pdf_image_reader = PyPDF2.PdfReader(open(pdf_path, "rb"))
content = ''
for i in range(len(pdf_file.pages)):
page_text = pdf_file.pages[i]
# page.extract_text()函数即读取文本内容
page_content = page_text.extract_text() ###当页提取完的所有表格文本
tables = page_text.extract_table() #### 当页所有表格
for i1 in range(len(tables)):
tables[i1] = list(filter(None, tables[i1])) #### 过滤空值
if i ==3 :
print(tables)
print('-----------------------')
if i == 4 :
print(tables)
extract_content(path)
效果
第四页解析至末尾

第五页解析时跳过剩余表格了

原始文件 :
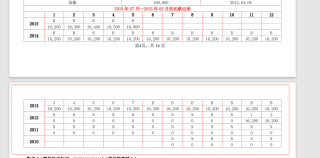
有什么办法可以把这种跨页的表格也解析完吗?









