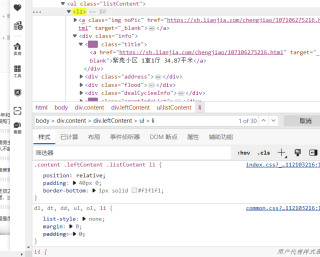
请问码友们我在爬取这个房地产数据的时候,为何从html上抓取信息失败了呀?代码显示print()输出值为空是怎么回事?明明selector路径是正确的。
for page in range(1, 5):
print('===========================正在下载第{}页数据================================'.format(page))
time.sleep(3)
url = 'https://sh/'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
response = requests.get(url=url, headers=headers)
html_data = response.text #字符串
selector = parsel.Selector(html_data)
lis = selector.css('body > div.content > div.leftContent > ul > li')
print(lis)