
数据集:
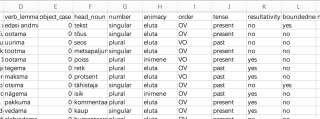
random factor:verb_lemma
自变量:number,animacy,order,tense,resultativity,boundedness
因变量:object_case (partitive 0,nominative 1)
代码如下:
m2 = glmer(object_case ~ number + animacy + order + tense + resultativity + boundedness + (1|verb_lemma),
data = my_dataset, family=binomial(link = "logit"),
control=glmerControl(optimizer = "bobyqa"))
summary(m2)
数据如下
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) ['glmerMod']
Family: binomial ( logit )
Formula: object_case ~ number + animacy + order + tense + resultativity + boundedness + (1 | verb_lemma)
Data: lra
Control: glmerControl(optimizer = "bobyqa")
AIC BIC logLik deviance df.resid
139.1 173.7 -60.5 121.1 336
Scaled residuals:
Min 1Q Median 3Q Max
-0.5317 0.0000 0.0000 0.0007 0.5398
Random effects:
Groups Name Variance Std.Dev.
verb_lemma (Intercept) 1912 43.73
Number of obs: 345, groups: verb_lemma, 171
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -45.5773 10.3034 -4.424 9.71e-06 ***
numbersingular 2.4965 2.2802 1.095 0.274
animacyeluta -2.7037 4.8314 -0.560 0.576
animacyinimene -6.2863 5.8948 -1.066 0.286
orderVO -0.8728 2.2550 -0.387 0.699
tensepresent -0.0722 2.5892 -0.028 0.978
resultativityyes 37.1170 7.2732 5.103 3.34e-07 ***
boundednessyes 24.1356 4.3747 5.517 3.45e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) nmbrsn anmcyl anmcyn ordrVO tnsprs rslttv
numbersnglr -0.260
animacyelut -0.443 -0.384
animacyinmn -0.254 -0.292 0.846
orderVO -0.139 -0.106 0.187 0.178
tensepresnt -0.477 0.075 0.442 0.423 0.146
reslttvtyys -0.885 0.329 0.082 -0.106 -0.126 0.271
bounddnssys -0.537 0.370 -0.295 -0.544 -0.023 -0.062 0.680
请问根据这些所得到的数据怎么解释自变量(6个),因变量以及随机变量间的关系?或者有可视化这些数据的必要吗(麻烦给一下代码)?提前感谢帮忙,文科生真的搞不会T_T









