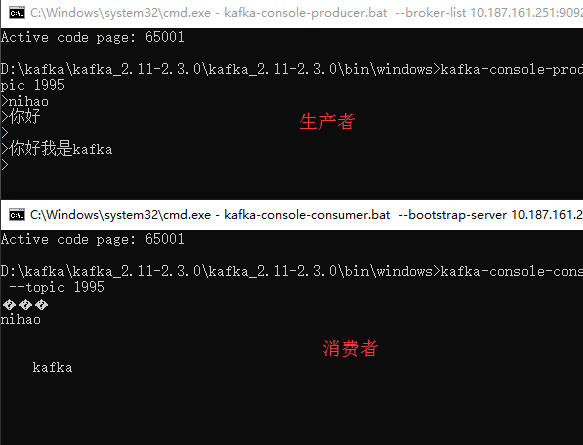
 cmd操作kafka 生产者与消费者 传递之后是乱码 后通过chcp改为utf-8编码格式 直接就空了 代码控制台输出是没有问题的,请问该怎么解决???
cmd操作kafka 生产者与消费者 传递之后是乱码 后通过chcp改为utf-8编码格式 直接就空了 代码控制台输出是没有问题的,请问该怎么解决???

kafka消息传递中文乱码

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2018-04-27 17:31回答 2 已采纳 1, 先确认你的网络有没有问题 2,在向服务器发起连接后,在kafka的服务器配置中有zookeeper.connect=xx.xx.xx.xx:2181的配置 这时候kafka会查找zookeep
- 2021-04-19 17:13回答 2 已采纳 连接问题 检查下ip和端口
- 2022-02-16 19:32回答 4 已采纳 重新开一个topic,然后先启动consumer,再启动producer,再发消息,你这个可能是consumer已经在broker里有了自己的offset,就会读不到之前producer发送到brok
- 2021-02-28 10:30圆滚滚的豆豆的博客 今天遇到一个问题就是在Action当中把一条...现解决办法如下:1、对要进行URL传递的中文字符进行编码:String message =Java.NET.URLEncoder.encode("中文字符","utf-8");2、在取URL传递中文的页面对字符进行解码:...
- 2022-10-25 09:26回答 5 已采纳 感觉消息堆积有点厉害,查一下代码,是因为什么原因导致消息一直没被消费。如果只是前端数据,可以丢弃的话,把队列清空,看看还会不会卡?
- 2022-08-23 10:01回答 1 已采纳 同一个消费组能同时消费的消费者数量和topic的分区数有关,估计是你的topic只有两个分区所以使用相同的groupid只有两个消费者在消费,加一个分区就好
- 2022-06-11 10:41回答 1 已采纳 给你个例子,是可以收发的。验证通过再和你的对比一下,你应该哪里配错了。 springboot集成kafka、消息发送、消费使用_‘’小磊的博客-CSDN博客_spri
- 2023-03-22 17:19+uuid+的博客 Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅...
- 2021-09-14 10:43回答 3 已采纳 先不论用什么来实现,我们先评估业务。 1、你用消息,你要明白,你这个消息,消费的时候需要不需要回复已已消费?2、你能不能重复消费消息?3、如果消息丢失了怎么办?4、另外,这些消息是怎么一个消费规律?一
- 2021-07-02 11:07回答 2 已采纳 对kafka来说,只要这条数据发出去了,就算消费了,你消费者怎么处理,和kafka无关了。对消费者来说, 你只需要消费下一条就行了。至于偏移量, 你第一次消费的时候,是要发送偏移的,这个你消费者要本地
- 2022-12-20 23:32回答 1 已采纳 消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。如果消息Pro
- 2022-09-23 11:00chosen-1-S的博客 kafka的传统定义:kafka是一个分布式的基于发布\订阅模式的消息队列,主要用于大数据实时处理领域kafka的最新概念:kafka是一个开源的分布式事件流平台,(80%的公司都在用),用于高性能数据管道、流分析、数据集成...
- 2021-08-16 15:59回答 1 已采纳 应该可以,不过通常使用scala语言进行编写
- 2024-01-29 15:36_L_J_H_的博客 SpringBoot 整合 Kafka 发送 和 接收消息(使用 KafkaTemplate 发送消息 和 使用 @KafkaListener 修饰监听器来接收消息)
- 2022-08-16 19:39以终为始001的博客 综上所述:生产者和消费者的序列化器必须是相同的,否则可能就会出现乱码的情况 下面是kafka的序列化接口的官方定义:表明了必须将我们发送的消息转化为字节数组 下面是kafka的序列化接口的定义: public interface...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 ubuntu子系统密码忘记
- ¥15 信号傅里叶变换在matlab上遇到的小问题请求帮助
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作
- ¥15 求NPF226060磁芯的详细资料
- ¥15 使用R语言marginaleffects包进行边际效应图绘制
- ¥20 usb设备兼容性问题
- ¥15 错误(10048): “调用exui内部功能”库命令的参数“参数4”不能接受空数据。怎么解决啊
- ¥15 安装svn网络有问题怎么办
- ¥15 vue2登录调用后端接口如何实现