1.如将带中文的字符串转成unicode的格式,然后如何再转回来,
注:字符串中既有英文又有中文
代码由C语言实现。

1.如将带中文的字符串转成unicode的格式,然后如何再转回来,
注:字符串中既有英文又有中文
代码由C语言实现。
 分享
分享
https://www.cnblogs.com/cfas/p/7931787.html
这个试试
/*****************************************************************************
* 将一个字符的UTF8编码转换成Unicode(UCS-2和UCS-4)编码.
*
* 参数:
* pInput 指向输入缓冲区, 以UTF-8编码
* Unic 指向输出缓冲区, 其保存的数据即是Unicode编码值,
* 类型为unsigned long .
*
* 返回值:
* 成功则返回该字符的UTF8编码所占用的字节数; 失败则返回0.
*
* 注意:
* 1. UTF8没有字节序问题, 但是Unicode有字节序要求;
* 字节序分为大端(Big Endian)和小端(Little Endian)两种;
* 在Intel处理器中采用小端法表示, 在此采用小端法表示. (低地址存低位)
****************************************************************************/
int enc_utf8_to_unicode_one( const /*unsigned*/ char* pInput, unsigned int length,/*unsigned*/ char *Unic )
{
assert( pInput != NULL && Unic != NULL );
// b1 表示UTF-8编码的pInput中的高字节, b2 表示次高字节, ...
char b1, b2, b3, b4, b5, b6;
int utfbytes = 0;
unsigned char *pOutput = ( unsigned char * )Unic;
int n = 0;
while ( true )
{
//*Unic = 0x0; // 把 *Unic 初始化为全零
utfbytes = enc_get_utf8_size( *pInput );
switch ( utfbytes )
{
case 0:
*pOutput = *pInput;
utfbytes += 1;
break;
case 2:
b1 = *pInput;
b2 = *( pInput + 1 );
if ( ( b2 & 0xE0 ) != 0x80 )
return 0;
*pOutput = ( b1 << 6 ) + ( b2 & 0x3F );
*( pOutput + 1 ) = ( b1 >> 2 ) & 0x07;
break;
case 3:
b1 = *pInput;
b2 = *( ++pInput );
b3 = *( ++pInput );
if ( ( ( b2 & 0xC0 ) != 0x80 ) || ( ( b3 & 0xC0 ) != 0x80 ) )
return 0;
*(pOutput+n) = ( b2 << 6 ) + ( b3 & 0x3F );
*( pOutput+n+1 ) = ( b1 << 4 ) + ( ( b2 >> 2 ) & 0x0F );
n += 2;
break;
case 4:
b1 = *pInput;
b2 = *( pInput + 1 );
b3 = *( pInput + 2 );
b4 = *( pInput + 3 );
if ( ( ( b2 & 0xC0 ) != 0x80 ) || ( ( b3 & 0xC0 ) != 0x80 )
|| ( ( b4 & 0xC0 ) != 0x80 ) )
return 0;
*pOutput = ( b3 << 6 ) + ( b4 & 0x3F );
*( pOutput + 1 ) = ( b2 << 4 ) + ( ( b3 >> 2 ) & 0x0F );
*( pOutput + 2 ) = ( ( b1 << 2 ) & 0x1C ) + ( ( b2 >> 4 ) & 0x03 );
break;
case 5:
b1 = *pInput;
b2 = *( pInput + 1 );
b3 = *( pInput + 2 );
b4 = *( pInput + 3 );
b5 = *( pInput + 4 );
if ( ( ( b2 & 0xC0 ) != 0x80 ) || ( ( b3 & 0xC0 ) != 0x80 )
|| ( ( b4 & 0xC0 ) != 0x80 ) || ( ( b5 & 0xC0 ) != 0x80 ) )
return 0;
*pOutput = ( b4 << 6 ) + ( b5 & 0x3F );
*( pOutput + 1 ) = ( b3 << 4 ) + ( ( b4 >> 2 ) & 0x0F );
*( pOutput + 2 ) = ( b2 << 2 ) + ( ( b3 >> 4 ) & 0x03 );
*( pOutput + 3 ) = ( b1 << 6 );
break;
case 6:
b1 = *pInput;
b2 = *( pInput + 1 );
b3 = *( pInput + 2 );
b4 = *( pInput + 3 );
b5 = *( pInput + 4 );
b6 = *( pInput + 5 );
if ( ( ( b2 & 0xC0 ) != 0x80 ) || ( ( b3 & 0xC0 ) != 0x80 )
|| ( ( b4 & 0xC0 ) != 0x80 ) || ( ( b5 & 0xC0 ) != 0x80 )
|| ( ( b6 & 0xC0 ) != 0x80 ) )
return 0;
*pOutput = ( b5 << 6 ) + ( b6 & 0x3F );
*( pOutput + 1 ) = ( b5 << 4 ) + ( ( b6 >> 2 ) & 0x0F );
*( pOutput + 2 ) = ( b3 << 2 ) + ( ( b4 >> 4 ) & 0x03 );
*( pOutput + 3 ) = ( ( b1 << 6 ) & 0x40 ) + ( b2 & 0x3F );
break;
default:
return 0;
break;
}
length -= utfbytes;
if ( length <= 0 )
break;
else
++pInput;
}
return utfbytes;
}
int main( int argc, char** argv )
{
string utf8 = CodeConverter::UnicodeToUtf8( L"成都" );
wstring unicode = CodeConverter::Utf8ToUnicode( wsdd );
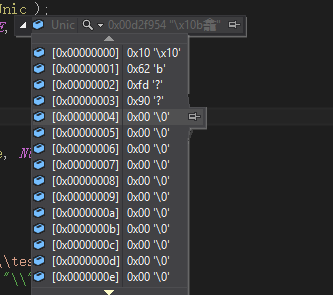
char Unic[ 512 ] = { 0 };
enc_utf8_to_unicode_one( wsdd.c_str(), wsdd.size(), Unic );
}
分享



