avro格式定义如下图: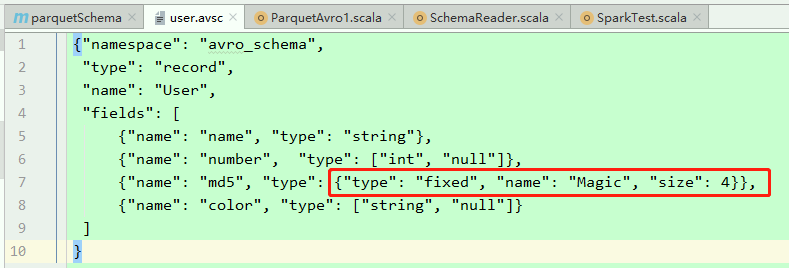
然后spark正常读取生成的parquet则报错:Illegal Parquet type: FIXED_LEN_BYTE_ARRAY。问怎么读取parquet(不一定要用spark)?详细错误如下:
org.apache.spark.sql.AnalysisException: Illegal Parquet type: FIXED_LEN_BYTE_ARRAY;
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.illegalType$1(ParquetSchemaConverter.scala:107)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convertPrimitiveField(ParquetSchemaConverter.scala:175)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convertField(ParquetSchemaConverter.scala:89)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.$anonfun$convert$1(ParquetSchemaConverter.scala:71)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at scala.collection.TraversableLike.map(TraversableLike.scala:237)
at scala.collection.TraversableLike.map$(TraversableLike.scala:230)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convert(ParquetSchemaConverter.scala:65)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convert(ParquetSchemaConverter.scala:62)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.$anonfun$readSchemaFromFooter$2(ParquetFileFormat.scala:664)
at scala.Option.getOrElse(Option.scala:138)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.readSchemaFromFooter(ParquetFileFormat.scala:664)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.$anonfun$mergeSchemasInParallel$2(ParquetFileFormat.scala:621)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2(RDD.scala:801)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2$adapted(RDD.scala:801)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)

spark读取avro序列化的parquet时报错:Illegal Parquet type: FIXED_LEN_BYTE_ARRAY

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 大大怪打LZR 2023-08-13 21:49关注
大大怪打LZR 2023-08-13 21:49关注根据您提供的错误信息,似乎问题出在Parquet文件的数据类型不匹配上。Parquet文件中的数据类型与读取器(例如Spark)期望的数据类型不一致。
根据您的问题描述,您的Avro架构定义中可能使用了
FIXED数据类型,而这在Parquet文件中通常对应于FIXED_LEN_BYTE_ARRAY类型。然而,Spark 默认情况下可能不支持直接将 Parquet 文件中的FIXED_LEN_BYTE_ARRAY数据类型映射到 Spark 数据类型。为了解决这个问题,您可以考虑以下几种方法:
自定义Schema映射: 尝试使用自定义的Schema映射来将 Parquet 文件中的
FIXED_LEN_BYTE_ARRAY数据类型转换为Spark支持的数据类型。您可以通过在读取Parquet文件时提供一个自定义的Schema来实现这一点。升级Spark版本: 有时候问题可能是特定版本的Spark引起的,尝试升级到较新的Spark版本可能会解决某些问题,因为Spark不断在版本中改进Parquet读写支持。
数据转换: 在读取Parquet文件之前,将其转换为适合Spark的数据格式,例如CSV或JSON。然后,您可以使用Spark读取这些转换后的文件。
Parquet工具: 使用Parquet文件的命令行工具,例如Apache Parquet Tools,可以提供关于Parquet文件的更多信息,有时可以揭示出数据类型不匹配的问题。
最好的方法可能会取决于您的具体情况。您还可以根据具体的Avro架构和Parquet文件内容,尝试调整Schema映射或转换数据格式以解决问题。
解决 无用评论 打赏举报 分享
- 2021-04-29 14:0210. **结果持久化**:处理后的数据可能被保存回Hive表,或者以其他格式(如Parquet、Avro)存储在HDFS上,便于后续查询和分析。 11. **监控与调优**:项目可能包含性能监控和调优的部分,比如检查Stage的执行时间,...
- 2022-11-15 00:00肥叔菌的博客 avro–>AVRO;将env_cmd.data, java_cmd, format, gp_hadoop_connector_version, url, table_schema.data, table_attr_names.data序列化为cmd,最后调用。gphdfs_fopen函数通过调用hadoop_env.sh脚本建立Hadoop环境...
- 2017-01-11 10:56yykxt的博客 本篇博文译自Spark2.0.2官方文档,以供自己学习及大家参考,如转载请注明。
- 2023-12-13 15:22code@fzk的博客 使用parquet格式Avro数据序列化过程中报错,报错原因:Avro对字段名有校验,只支持字母和下划线开头[A-Za-z_],本次报错Illegal initial character:` $ip`就是使用了`$ip`字段名,字段名`$`开头所以校
- 2018-10-19 11:02撸码小丑的博客 自定义 Hive 序列化/反序列化(Serializer/Deserializer) 类(SerDes)。Impala 支持一组通用的本地文件格式,在 CDH 中有对应的内置的 SerDes。参见 How Impala Works with Hadoop File Formats 了解详细信息 ...
- 没有解决我的问题, 去提问

