根据k-means聚类分割热图
我的Heatmap代码如下
Heatmap(sample_random,column_title = "Signature",row_title = "Sample",show_row_names = FALSE,km=2)
但是不同的数据,绘制的热图hot和cold分布区域不固定,如下图的两个数据
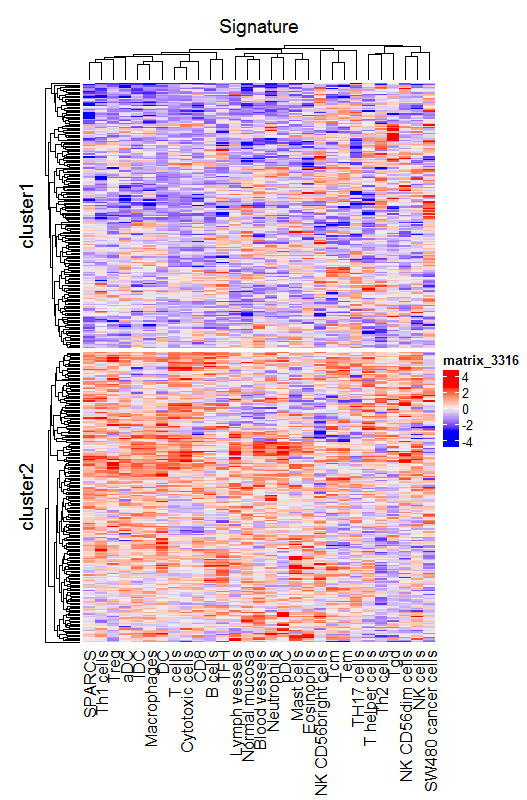
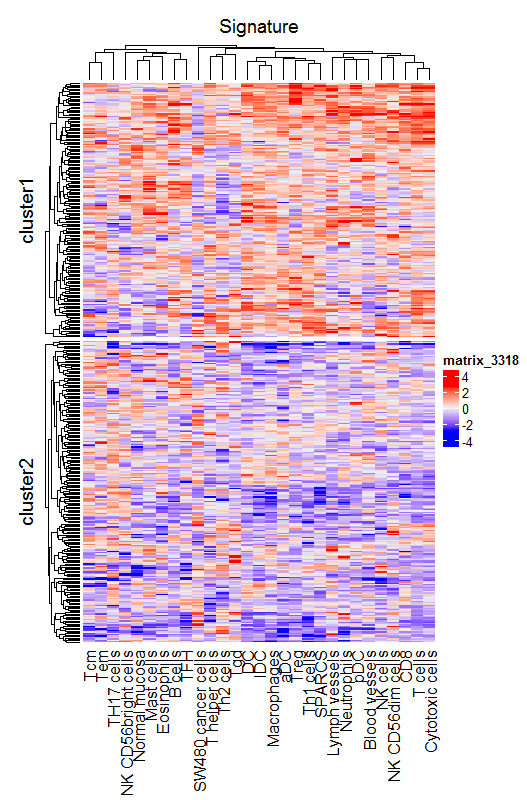
有什么方法可以让hot也就是红色部分固定在cluster1吗?

根据k-means聚类分割热图
我的Heatmap代码如下
Heatmap(sample_random,column_title = "Signature",row_title = "Sample",show_row_names = FALSE,km=2)
但是不同的数据,绘制的热图hot和cold分布区域不固定,如下图的两个数据
有什么方法可以让hot也就是红色部分固定在cluster1吗?
 分享
分享
 关注
关注让阿豪来帮你解答,本回答参考chatgpt3.5编写提供,如果还有疑问可以评论或留言为了让热图中的红色部分(即hot区域)固定在cluster1,可以通过调整k-means算法中的初始质心位置或者调整聚类的参数来实现。 一种方法是手动指定k-means算法的初始质心位置,将簇1的质心初始位置设置在红色部分的中心。这样可以强制簇1包含红色区域,从而使得红色部分固定在cluster1。 下面是一个简单的示例代码,展示了如何手动指定k-means的初始质心位置:
# 手动指定初始质心位置
initial_centers <- matrix(c(x1, y1), nrow = 1) # 将簇1的质心设为(x1, y1)
km_result <- kmeans(data, centers = initial_centers, nstart = 1) # 运行k-means算法
# 绘制热图
Heatmap(sample_random,column_title = "Signature",row_title = "Sample",show_row_names = FALSE, km = km_result$cluster)
另一种方法是通过调整k-means算法的参数来控制聚类的结果。可以尝试增加迭代次数或者调整扰动参数,以获得更加稳定的聚类结果。
# 调整k-means参数
km_result <- kmeans(data, centers = 2, nstart = 10, iter.max = 100) # 增加迭代次数和尝试次数
# 绘制热图
Heatmap(sample_random,column_title = "Signature",row_title = "Sample",show_row_names = FALSE, km = km_result$cluster)
通过这两种方法的调整,可以尝试固定红色部分在cluster1的位置。需要根据具体的数据特点和需求来进行调整。
分享

