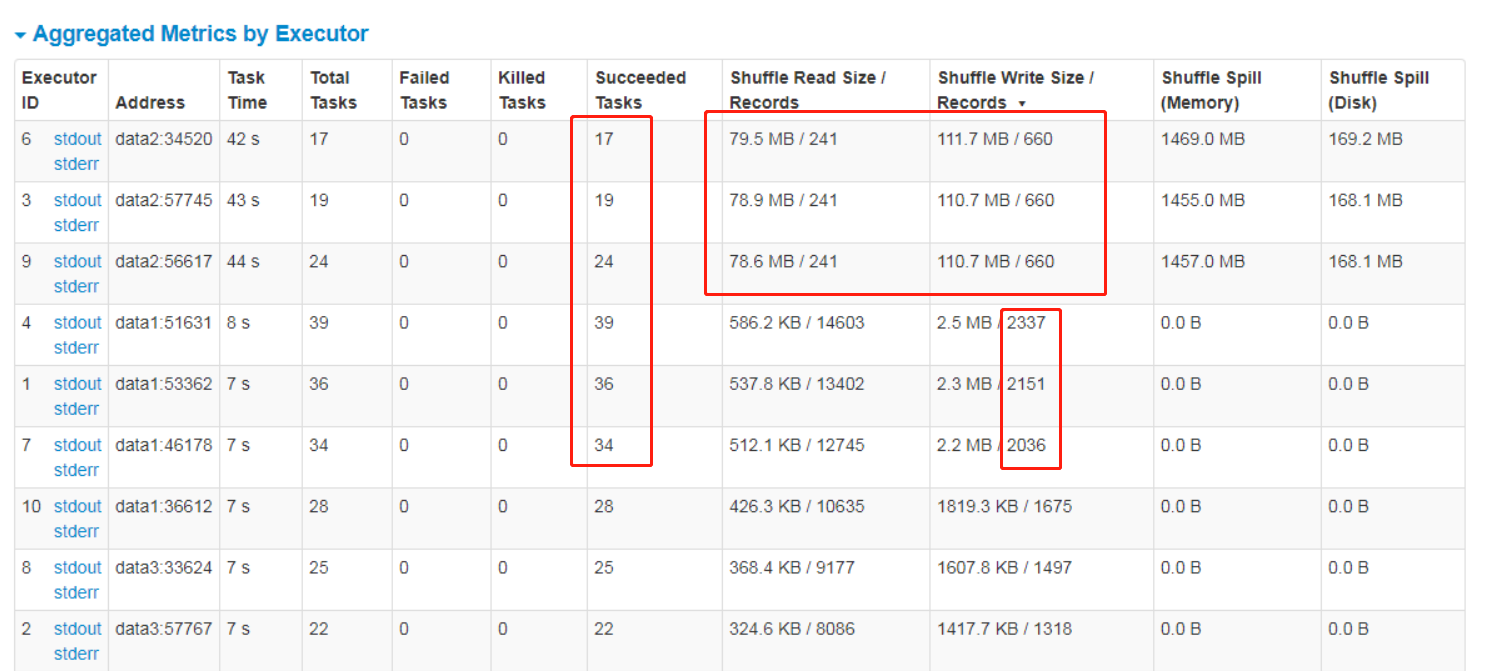
是这样的,我跑spark任务,我发现总是卡在最后3个task上面,然后一看发现都在data2上面,为啥这3个executor的tasks的数量比其他要少,而且记录数少。

spark的一个疑问,请大神解答。

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

 关注
关注让阿豪来帮你解答,本回答参考chatgpt3.5编写提供,如果还有疑问可以评论或留言
问题分析:- 可能是由于数据倾斜导致部分executor上的task数量较少,而且记录数也较少。
- 可能是数据分区不均匀导致某些executor上的task数量较少。 解决方案:
- 检查数据分布情况,看是否存在数据倾斜。可以通过查看数据2的分布情况,可能需要重新进行数据分区。
- 调整任务调度策略,比如尝试使用动态分配资源策略,平衡executor上的task数量。 案例: 假设数据2是一个DataFrame,使用Spark进行处理时,可以通过以下代码查看数据分布情况:
val data2 = spark.read.format("csv").load("path_to_data2") data2.groupBy("column_name").count().show()如果发现数据倾斜或数据分区不均匀,可以调整数据分区方式或调度策略。
解决 无用评论 打赏举报 分享
- 2025-08-07 22:22QQ2079523559的博客 基于 Spark 的国内售车数据分析与处理大数据系统,依托 Spark 的分布式计算框架(Spark SQL、DataFrame API、MLlib),构建覆盖全渠道售车数据的采集、清洗、分析与挖掘的全流程处理体系。 系统整合多源售车数据(4S...
- 2025-08-07 22:13QQ2079523559的博客 基于 Spark 的小说推荐和可视化分析系统,依托 Spark 的分布式计算能力(MLlib 机器学习库、Spark Streaming 实时处理)与可视化工具(ECharts、Tableau),构建集智能推荐、内容分析、阅读行为洞察于一体的综合平台...
- 2025-08-07 22:21QQ2079523559的博客 基于 Spark 的新能源汽车销售数据可视化系统,依托 Spark 的分布式计算能力(Spark SQL 高效处理)与可视化工具(ECharts、Plotly),构建多维度、交互式的销售数据可视化平台。 系统整合多源销售数据(区域销量、...
- 2020-12-11 03:06weixin_39752788的博客 Python 的排名从去年开始就借助人工智能持续上升,现在它已经成为了第一名。Python的火热,也带动了工程师们的就业热。今天我们来看看Python工程师在企业里面的定位到底是什么。Python工程师在企业里四个重要的定位...
- 2025-08-07 22:23QQ2079523559的博客 基于 Spark 和协同过滤的婴幼儿产品推荐系统,依托 Spark 的分布式计算能力(MLlib 机器学习库、DataFrame API)与协同过滤算法,构建高效精准的产品推荐体系。 系统整合多源数据(用户购买记录、浏览行为、评价评分...
- 2018-11-02 14:03乐天AI笔记的博客 500篇干货解读人工智能新时代 本文主要目的是为了分享一些机器学习以及深度学习的资料供大家参考学习,整理了大约500份国内外优秀的材料文章,打破一些学习人工智能领域没头绪同学的学习禁锢,希望看到文章的朋友...
- 2019-05-24 09:30VIP_CQCRE的博客 包括一位清华AI博士 @Beck Wang,一位计算机视觉方向的专家 @Angela,一位百度的数据挖掘工程师@熊猫酱,以具体工作流为核心,针对学习者各个机器学习核心能力进行培养,举办了一个为期8天的人工智能训练营。...
- 2019-06-17 08:04weixin_33805743的博客 大家好,我是chris,入行前5年在一家上市游戏公司做算法,从数据挖掘算法在业务线落地开始,涉及机器... 在外行人眼中,算法工程师可能拿到最近某大神新发的Paper,或者自己钻研理论推公式产出理论成果,通过并行...
- 2025-07-25 16:57whaosoft-143的博客 而 Agent KB 增强的 agent 则能够应用经验驱动的规则:智能过滤 ANISOU/HETATM 记录,专注于真正的 ATOM 条目,并通过 N-CA 键长范围的合理性检查进行验证,最终精准提取骨架 N-CA 原子对,报告出正确的 1.456 Å ...
- 2018-02-07 15:50weixin_33875839的博客 本文主要目的是为了分享一些机器学习以及深度学习的资料供大家参考学习,整理了大约500份国内外优秀的材料文章,打破一些学习人工智能领域没头绪同学的学习禁锢,希望看到文章的朋友能够学到更多,此外:某些资料在...
- 没有解决我的问题, 去提问
