在小程序中使用towxml解析时,Markdown能够正常解析,但解析HTML时,头部和尾部会出现部分乱码。
尤其是解析公众号文章时出现全部乱码。
下方分别是 解析Markdown、解析普通html、解析公众号所显示的页面
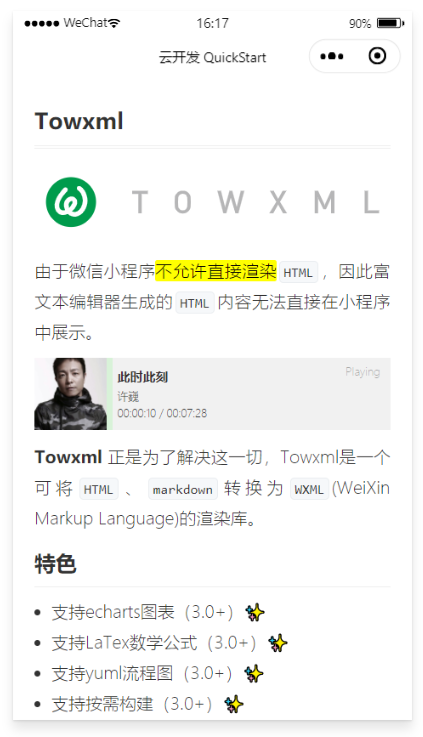


求大佬指教这是怎么一回事?

在小程序中使用towxml解析时,Markdown能够正常解析,但解析HTML时,头部和尾部会出现部分乱码。
尤其是解析公众号文章时出现全部乱码。
下方分别是 解析Markdown、解析普通html、解析公众号所显示的页面
求大佬指教这是怎么一回事?
 分享
分享
参考GPT和自己的思路:
对于你提出的问题,我认为可能存在以下几种情况:
towxml对HTML的解析不够完善,导致某些标签或属性没有被正确解析,从而导致出现乱码。
公众号文章中可能存在一些不规范的HTML标签或属性,从而导致towxml解析出错,进而导致出现乱码。
towxml的配置可能需要进一步优化,例如增加指定编码方式的选项等。
建议你联系towxml的开发者了解更多详细信息,并升级至最新版本,同时也可以查看towxml的文档和GitHub问题页以获得更多解决方案。
分享

