根据肘部定理选择K=2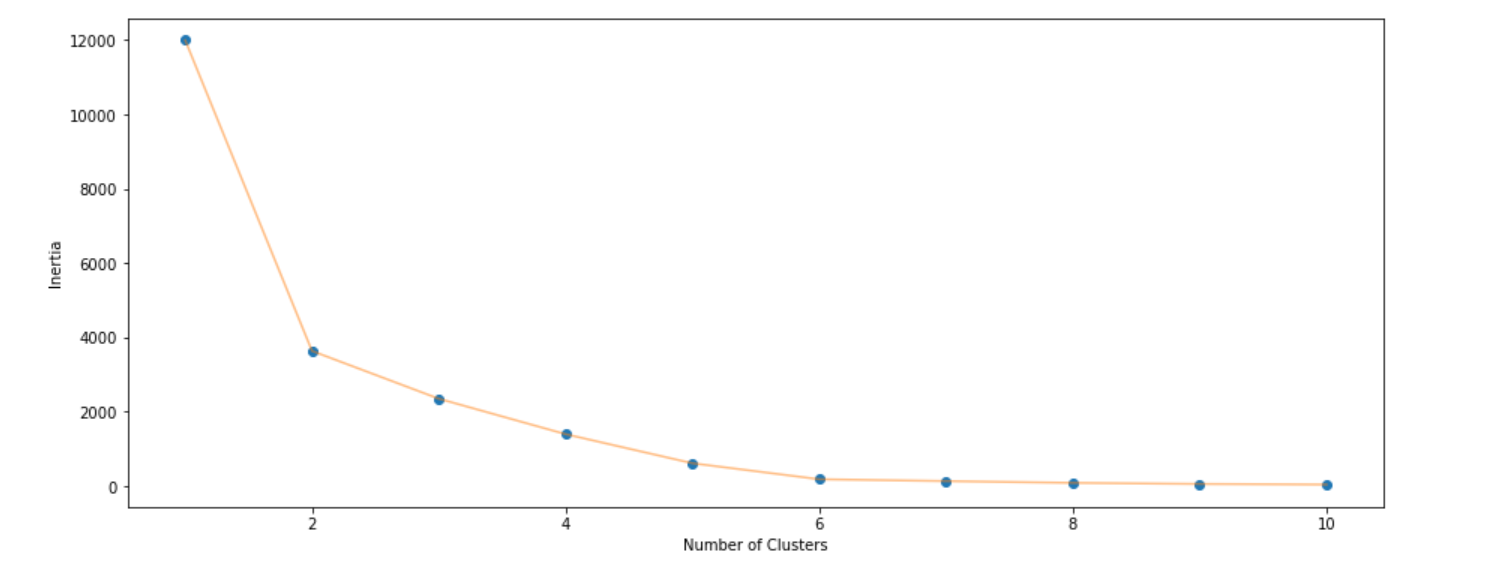

k-means聚类效果不佳,怎么办啊

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

 关注不知道你这个问题是否已经解决, 如果还没有解决的话:
关注不知道你这个问题是否已经解决, 如果还没有解决的话:- 看下这篇博客,也许你就懂了,链接:K-means聚类 实验报告
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^解决 无用评论 打赏举报 分享
- 2025-12-23 19:56hbz4491的博客 K-means是一种基于距离的聚类算法,通过迭代优化将数据划分为K个簇。其核心步骤包括:随机初始化K个质心,将每个点分配到最近质心,重新计算质心位置,直至收敛。算法使用欧氏距离最小化簇内平方误差和(WCSS),时间...
- 2024-05-26 22:44Papicatch的博客 K-means聚类是一种常见且高效的无监督学习算法,用于将数据集分成K个簇(clusters)。本文将详细介绍K-means聚类的基本原理、算法步骤、优缺点以及应用场景。
- 2023-12-12 20:27JiaYu嵌入式的博客 K-means是一种常用的聚类算法,用于将数据集中的观测点分为不同的群组或簇。聚类是一种无监督学习方法,其目标是发现数据中隐藏的结构,将相似的数据点划分为同一组,同时将不相似的数据点划分为不同的组。
- 2024-04-07 15:48云天徽上的博客 在众多聚类算法中,K-means算法因其简单高效而备受青睐。K-means算法的基本思想是:通过迭代的方式,将数据划分为K个不同的簇,并使得每个数据点与其所属簇的质心(或称为中心点、均值点)之间的距离之和最小。具体...
- 2025-03-19 21:532201_75491841的博客 K-Means聚类是一种无监督学习算法,用于将数据集划分为K个簇(cluster)。每个簇中的数据点彼此相似,而不同簇之间的数据点则尽可能不同。K-Means聚类算法的目标是最小化簇内数据点与簇中心(centroid)之间的距离...
- 2025-05-19 18:11K-means聚类算法是无监督学习领域中一个非常重要的算法,它广泛应用于数据挖掘、模式识别、图像分割、市场细分等领域。K-means算法通过迭代的方式,将数据划分为K个聚类,使得每个数据点属于其最近的聚类中心的聚类...
- 2025-10-11 02:03android的博客 本文探讨了K-means聚类与朴素贝叶斯分类器结合的混合机器学习方法,涵盖其在智能空调监控、图像分类、文本文档分类、员工绩效预测及异常检测等多个领域的应用。文章详细介绍了随机森林、无监督学习和划分聚类的基本...
- 2024-05-23 02:14Python老吕的博客 K-means聚类模型是一种简单而有效的无监督学习算法,具有广泛的应用前景。然而,由于其存在一些固有的缺点,如需要预先设定K值、对初始点敏感等,使得在实际应用中需要谨慎选择算法参数,并结合具体场景进行优化和...
- 2025-08-09 21:37山烛的博客 K-means 聚类算法以其简单、高效的特点,在数据分析领域有着重要的地位。通过本文的学习,我们了解了 K-means 的基本原理、优势与局限性,并结合啤酒数据进行了实战演练,同时也深入解析了 sklearn 中 KMeans 的 API...
- 2024-07-10 14:37I'mAlex的博客 通过选择合适的 K 值、优化初始化方法、并行化处理和内存优化,可以显著提高 K-means 算法的性能和效果。本文详细介绍了 K-means 聚类算法的原理、应用、优化方法,并通过具体的示例代码帮助初学者理解和实现这一...
- 2023-05-05 01:13小白脸cty的博客 下面是K-means聚类算法的基本原理:初始化:首先,选择要将数据集分成k个簇,然后随机选择k个数据点作为初始簇中心。分配:将每个数据点分配到距离其最近的簇中心,每个数据点只能属于一个簇。更新:根据分配的数据...
- 2022-07-04 10:05小白学视觉的博客 点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达k-means算法是非监督聚类最常用的一种方法,因其算法简单和很好的适用于大样本数据,广泛应用于不同领域,本文详细总结了k-means聚类算法原理...
- 2022-09-11 16:49Sonhhxg_柒的博客 聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来说,你并不...
- 2025-09-16 13:18在数据挖掘领域中,k-means聚类算法是一种非常经典和广泛使用的无监督学习算法,它可以将数据集中的数据点根据距离远近分成k个簇,使得簇内的数据点之间相似度较高,而簇间相似度较低。 在MATLAB环境中实现k-means...
- 2024-12-13 19:08自信的小螺丝钉的博客 【AI知识】无监督学习之K-means 聚类算法+代码+过程可视化
- 没有解决我的问题, 去提问

