
如以下代码片段:
pd_df = pd.DataFrame(it)
df = spark.createDataFrame(pd_df, schema). \
filter("status = 6 AND power > 1000 AND speed >=6 AND speed <=20"). \
withColumn('device_code', F.lit(code))
df.show(1)
if df.count() > 0:
li.append(df)
在UI界面显示的show作业的DAG图为
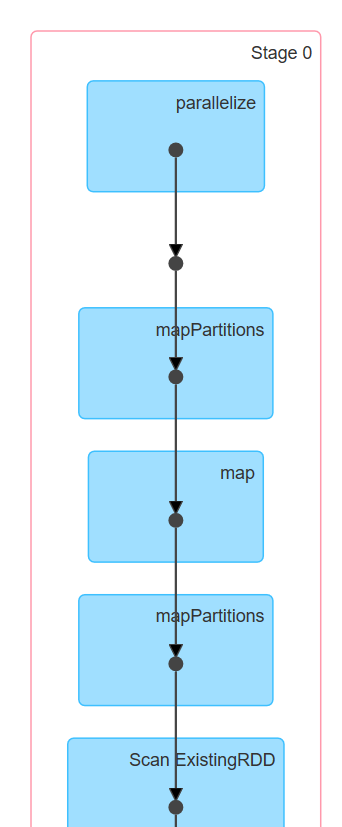

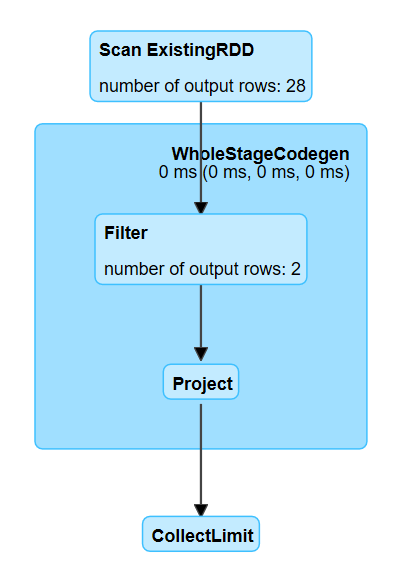
count作业的DAG图为
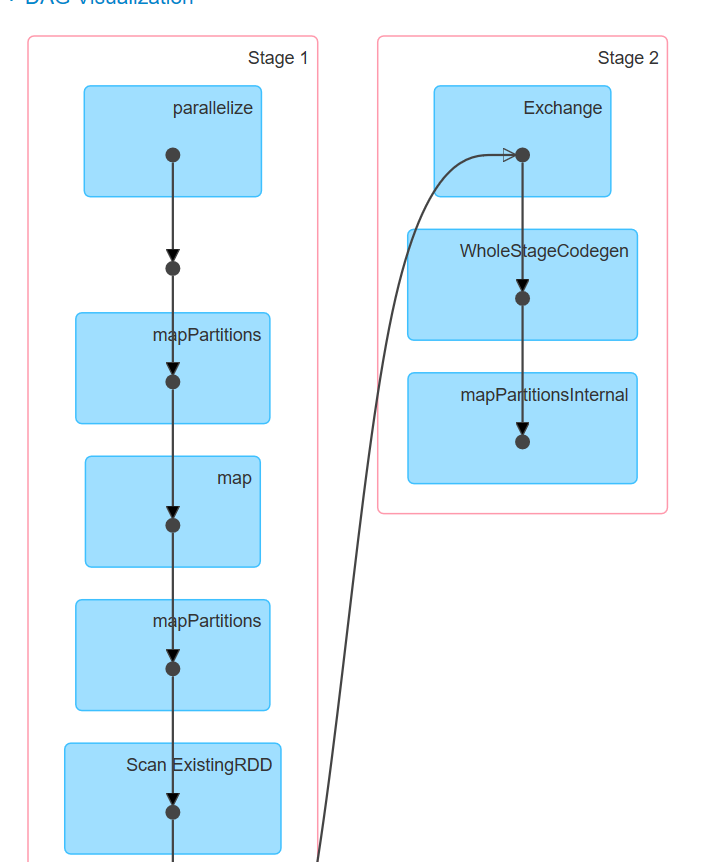

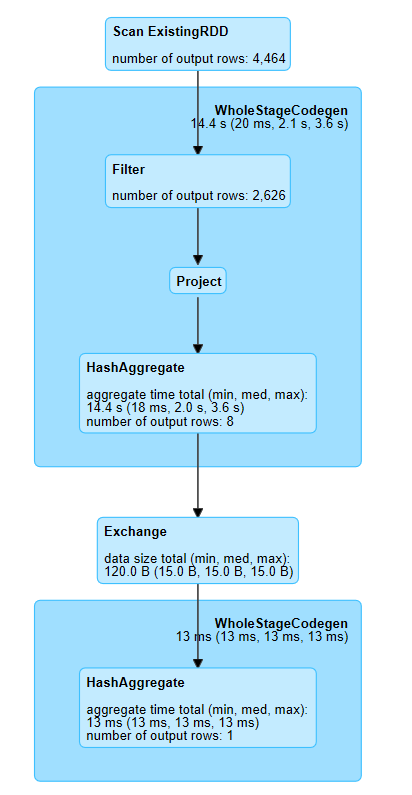
为什么在count作业就存在数据混洗?
count 和 show第一阶段应该都是指将python df转为spark df的过程把?为什么操作的并行度不一样?
count第二阶段为什么只有一个task?




