IDEA 运行 scala.class文件后报错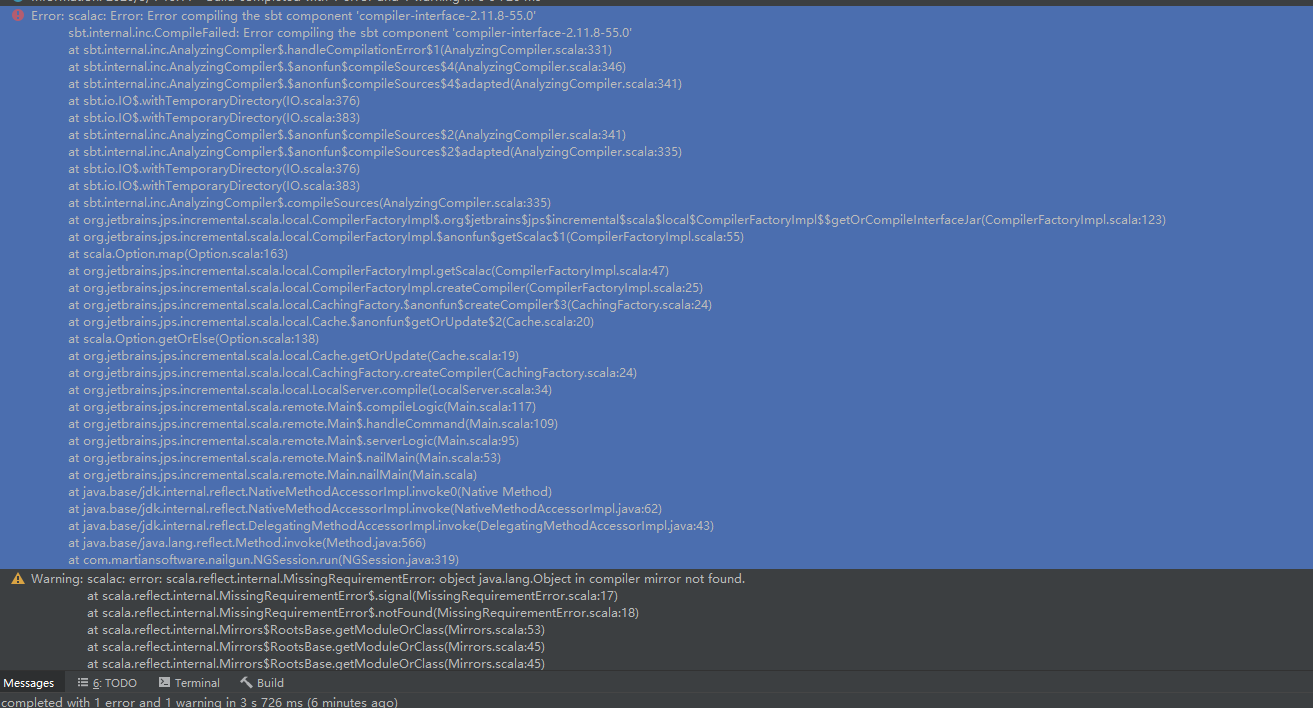

IDEA 运行 scala.class文件后报错

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2023-03-22 00:07回答 2 已采纳 这个错误很明显啊,被0除,83行那里,courseNames这个数组的长度为0。你可以看看对该数组赋值的地方,是不是出了什么问题,导致数组长度为0.
- 2021-11-11 13:29
 在IntelLij IDEA中下载了scala插件,IntelliJ IDEA版本 2021.1.1 x64,scala版本2021.1.22,jdk1.8.0_91。测试运行时报错
intellij-idea
scala
回答 2 已采纳 试试这样写,看看对不对 object HelloWorld { /* * 以下程序将输出'Hello World!' */ def main(args: Array[
在IntelLij IDEA中下载了scala插件,IntelliJ IDEA版本 2021.1.1 x64,scala版本2021.1.22,jdk1.8.0_91。测试运行时报错
intellij-idea
scala
回答 2 已采纳 试试这样写,看看对不对 object HelloWorld { /* * 以下程序将输出'Hello World!' */ def main(args: Array[ - 2022-11-16 20:47回答 1 已采纳 this.getClass.getClassLoader.getResourceAsStream("sprakstream.properties"))加载properties的方式不对,试试其它的方式
- 2022-04-30 00:47ReoNaAc的博客 由于spark版本和Scala-sdk版本不兼容导致报错 在cmd中查看spark版本 可以看到我的spark版本是2.2.0 再在cmd中查看scala版本 发现Scala的版本是2.13.1 经过查询发现 spark2.2.x版本的需要Scala版本为2.11 ...
- 2022-04-19 11:52回答 2 已采纳 依赖和依赖的版本都要对上
- 2015-12-05 10:50回答 1 已采纳 java.util.Map javaMap = new java.util.HashMap(); scala.collection.immutable.Map scalaImmutableMap =
- 2021-08-04 22:32回答 1 已采纳 zip插件直接拖到idea中就可以安装
- 2022-04-19 11:56水下游泳的博客 Idea运行scala项目报错 原因是程序不知道是哪种运行环境。 设置成本地模式运行即可 new SparkConf().setAppName("WordCount1").setMaster("local") 修改完之后运行即可成功 另外,sdk和jar包之类的基础配置就不...
- 2022-08-25 13:38回答 1 已采纳 000
- 2019-06-03 11:32回答 1 已采纳 解决办法就是, 把IDEA 使用的Gradle 版本降低, 我默认使用的是 5.1 , 这个项目可能依赖的比较旧 Preferences ---> Build, Executio
- 2022-01-11 10:12回答 2 已采纳 这是空指针异常,发生在读取数据那里,仔细检查一下数据是否有问题,估计是数据格式出现了问题或者路径输出了问题导致没有读取到自己想要的数据,无法被获取到,所以报了空异常
- 2021-01-04 17:41Thomas2143的博客 2 查看报错文件所在的pom 检查多个子项目各自pom 上面多处版本对比,确保一致性 另一个可能就是类似下面这种: <dependency> <groupId>com.owlike</groupId> <artifactId>genson-scala...
- 2022-09-08 13:07回答 1 已采纳 先把环境变量配好,完事了直接选就行,一般有默认1.8,你可以选你自己安装的
- 2022-04-15 14:38温wen而雅的博客 <groupId>org.apache.sparkgroupId> <artifactId>spark-core_2.12artifactId> <version>3.0.0version> dependency> dependencies> 当pom.xml只加入spark依赖打包后的jar包的文件内容如下: jar包中并未包含scala相关...
- 2021-03-08 06:56weixin_39649478的博客 java.util.list 报错[2021-02-08 12:27:05]简介:php去除nbsp的方法:首先创建一个PHP代码示例文件;然后通过“preg_replace("/(\s|\ \;| |\xc2\xa0)/", " ", strip_tags($val));”方法去除所有nbsp即可。...
- 没有解决我的问题, 去提问

悬赏问题
- ¥15 基于卷积神经网络的声纹识别
- ¥15 Python中的request,如何使用ssr节点,通过代理requests网页。本人在泰国,需要用大陆ip才能玩网页游戏,合法合规。
- ¥100 为什么这个恒流源电路不能恒流?
- ¥15 有偿求跨组件数据流路径图
- ¥15 写一个方法checkPerson,入参实体类Person,出参布尔值
- ¥15 我想咨询一下路面纹理三维点云数据处理的一些问题,上传的坐标文件里是怎么对无序点进行编号的,以及xy坐标在处理的时候是进行整体模型分片处理的吗
- ¥15 CSAPPattacklab
- ¥15 一直显示正在等待HID—ISP
- ¥15 Python turtle 画图
- ¥15 stm32开发clion时遇到的编译问题