在ulipad中写python代码,遇到中文代码乱码问题。贴出代码与异常,python版本3.4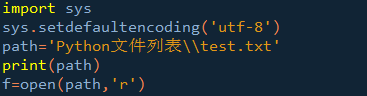
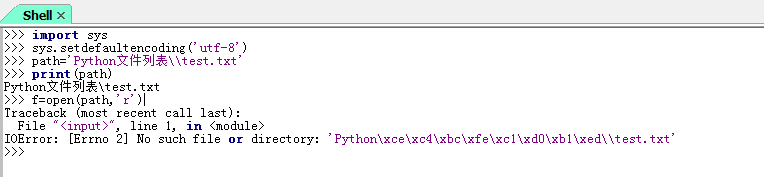

python中读取文件(路径含中文)出现乱码问题。

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


6条回答 默认 最新

- 2021-06-02 12:53回答 5 已采纳 把GBK改成UTF-8试一下,还有就是你的txt文档的编码格式不对。
- 2015-04-20 15:06回答 3 已采纳 [http://blog.csdn.net/zhaoxjzhao/article/details/7439159](http://blog.csdn.net/zhaoxjzhao/article/de
- 2021-09-13 23:25回答 2 已采纳 SQL Server中涉及到中文的缺省字符集是CP936,所以将charset配置为CP936,就解决了中文乱码的问题。 ```python import pymssql as sql connec
- 2020-09-20 04:18主要介绍了Python实现的json文件读取及中文乱码显示问题解决方法,涉及Python针对json文件的读取载入、编码转换等相关操作技巧,需要的朋友可以参考下
- 2021-08-17 16:12回答 2 已采纳 你输出下myfile这个对象,看看实际打开时使用的编码是什么。肯定不是utf-8
- 2022-05-09 21:50回答 1 已采纳 这应该不是乱码吧,你的数字太大,读出来以科学记数法的形式展示,可以看看这个https://www.jianshu.com/p/85342be4721f
- 2017-12-15 04:09回答 2 已采纳 你可以换用 Matplotlib。
- 2020-11-24 05:04weixin_39828715的博客 问题是这样的:用python写的程序,去读取一些目录和文件进行处理:比如说其中的中文目录名如下:示波器,曲线,卡哇伊小屋等等。然后比如示波器文件夹下面有下面文件:0.htm,0.png,示波...问题是这样的:用python写的...
- 2021-10-29 22:40回答 1 已采纳 pd.read_csv 方法中设置文件编码参数 encoding="utf-8"或encoding="gbk" data = pd.read_csv( r'F:\2021python学习\视频课件\
- 2015-05-25 15:44回答 1 已采纳 这个看上去unicode编码等。你的字符串中有中文标点符号吧
- 2022-03-25 21:26回答 2 已采纳 这个不是乱码, 是json数据
- 2020-11-24 05:04weixin_39537977的博客 设置默认编码在Python代码中的任何地方出现中文,编译时都会报错,这时可以在代码的首行添加相应说明,明确utf-8编码格式,可以解决一般情况下的中文报错。当然,编程中遇到具体问题还需具体分析啦。#encoding:ut...
- 2022-04-04 15:12回答 2 已采纳 参考 pandas如何禁用科学计数法,或者如何把二十位数字无损还原? - 知乎 dataframe中有一列科学计数法显示的float数据,每
- 2020-11-20 22:56weixin_39954487的博客 在使用python读取中文目录的名称的时候,会出现中文乱码的问题,该问题很严重,因为使用os.path.isdir('乱码名称')和ospath.isfile('乱码名称')是判断不正确,都为false。即使有时候采用 filename.decode("gbk")....
- 2020-09-20 15:18下面小编就为大家分享一篇解决Python2.7读写文件中的中文乱码问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 如何在scanpy上做差异基因和通路富集?
- ¥20 关于#硬件工程#的问题,请各位专家解答!
- ¥15 关于#matlab#的问题:期望的系统闭环传递函数为G(s)=wn^2/s^2+2¢wn+wn^2阻尼系数¢=0.707,使系统具有较小的超调量
- ¥15 FLUENT如何实现在堆积颗粒的上表面加载高斯热源
- ¥30 截图中的mathematics程序转换成matlab
- ¥15 动力学代码报错,维度不匹配
- ¥15 Power query添加列问题
- ¥50 Kubernetes&Fission&Eleasticsearch
- ¥15 報錯:Person is not mapped,如何解決?
- ¥15 c++头文件不能识别CDialog