用logstash解析带有中文的文档,解析出的数据有乱码?请问各位大神怎么解决啊??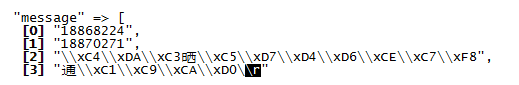

logstash中文乱码问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 wuhenzhe 2016-02-28 12:51关注
wuhenzhe 2016-02-28 12:51关注在input项里面指定编码方式啊,codec=>plain{charset=>"UTF-8"},然后output也这样指定;如果依然乱码,试一下把“UTF-8”换成“GB2312”。
按上面的方法基本上就可以解决了。
还有一种情况,就是你用的控制台输出的编码,造成的显示问题,所以建议你直接将logstash输出的数据写到文件里,然后用不同的编码方式打开~解决 无用评论 打赏举报 分享
- 2022-10-31 10:28回答 2 已采纳 你可以看下这个问题的回答https://ask.csdn.net/questions/7721331我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:logstash使用时遇见的报错
- 2017-06-09 07:21回答 2 已采纳 看我博客里面有,转换@timestamp,好用记得采纳 谢谢
- 2021-10-26 16:57回答 1 已采纳 经查询,代码中执行命令时,在后面加上 >out.log 2>&1 & 即可在代码中正常启动,完整的命令nohup /opt/logstash/logstash-7.5.0/bin/logs
- 2022-04-24 10:39zhcha_xr的博客 logstash 中文字段乱码问题 一、出现问题环境 最近接入深信服防火墙日志,该日志字段大多为中文字段。样本如下: <134>Dec 13 16:39:45 localhost fwlog: 日志类型:系统操作, 用户:admin(local), IP地址:...
- 2021-03-12 15:45回答 2 已采纳 先检查两个地方吧: 1./var/log/messages 和 /var/log/secure 下面有数据写入 (如果有数据写入,可以把logstash output 改为打印到控制台,看看logs
- 2021-12-28 15:11回答 1 已采纳 type"=>"illegal_argument_exception", "reason"=>"For input string: "2021-12-28T14:40:16.000Z"
- 2018-01-11 03:10回答 7 已采纳 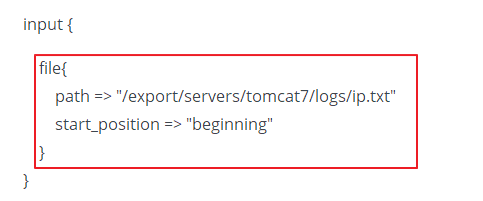 ## start_position 参数放在fi
- 2017-04-19 20:37Wang_Zhenwei的博客 使用Logstash读取日志的时候,常常会遇到中文乱码问题。不同文件字符集的对应logstash配置文件中的字符集。此处以linux系统下环境为例。 工具/原料 Vi编辑器 Linux基本命令 ...
- 2019-07-25 23:20回答 1 已采纳 这个帖子可以解决你的问题 https://github.com/elastic/logstash/issues/8901
- 2017-09-19 06:12回答 3 已采纳 或者直接使用正则的方式 http://www.cnblogs.com/Orgliny/p/5592186.html
- 2017-02-20 03:53回答 1 已采纳 Your problem can be solved very simply by changing the name of your timestamp variable since @time
- 2022-03-09 14:53归向的博客 用elk框架里的filebeat和logstah的时候遇到的一个小坑 在logstash的控制台上显示中文乱码。百度之后知道filebeat的input的编码要和文件的编码一致 举个例子 某个文件的编码格式 用nodepad+查看 为GB2312 我的...
- 2022-07-25 18:29回答 1 已采纳 什么安全代码权限?
- 2017-12-07 20:24风雨诗轩的博客 logstash版本为5.5.3,elasticsearch版本有两个,分别为2.3.0和5.5.3;其中elasticsearch-2.3.0运行在...本文所探讨的由logstash输出到elasticsearch所导致的中文乱码问题,其根本原因是操作系统编码不一样的问题。
- 2014-05-23 09:38suningcsdn的博客 有的文件中存在中文时,在kibana界面显示为乱码: 有的文件中存在中文时,在kibana界面可正常显示。 查看对应的文件的编码后,发现能正常显示的源文件为utf-8格式的。 请问下这个在logstas...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 基于卷积神经网络的声纹识别
- ¥15 Python中的request,如何使用ssr节点,通过代理requests网页。本人在泰国,需要用大陆ip才能玩网页游戏,合法合规。
- ¥100 为什么这个恒流源电路不能恒流?
- ¥15 有偿求跨组件数据流路径图
- ¥15 写一个方法checkPerson,入参实体类Person,出参布尔值
- ¥15 我想咨询一下路面纹理三维点云数据处理的一些问题,上传的坐标文件里是怎么对无序点进行编号的,以及xy坐标在处理的时候是进行整体模型分片处理的吗
- ¥15 CSAPPattacklab
- ¥15 一直显示正在等待HID—ISP
- ¥15 Python turtle 画图
- ¥15 stm32开发clion时遇到的编译问题