class Net:
def __init__(self,input_size,hidden_size,output_size,weight_init_std=0.001):
self.params={}
self.params['W1']=weight_init_std* \
np.random.randn(input_size,hidden_size)#高斯分布初始化
self.params['W2']=weight_init_std* \
np.random.randn(hidden_size,output_size)
self.params['b1']=np.zeros(hidden_size)
self.params['b2']=np.zeros(output_size)
def sigmoid(self,x):
x=np.array(x)
return 1/(1+np.exp(-x))
def softmax(self,x):
c=np.max(x)
exp_a=np.exp(x-c)#溢出对策
sum_exp=np.sum(exp_a)
y=exp_a/sum_exp
return y
def predict(self,x):
W1,W2=self.params['W1'],self.params['W2']
b1,b2=self.params['b1'],self.params['b2']
a1=np.dot(x,W1)+b1
z1=self.sigmoid(a1)
a2=np.dot(z1,W2)+b2
z2=self.sigmoid(a2)
y=self.softmax(z2)
return y
def loss(self,x,t):
y=self.predict(x)
if y.ndim==1:
t=t.reshape(1,t.size)
y=y.reshape(1,y.size)
batch_size=y.shape[0]
return -np.sum(t*np.log(y+1e-7))/batch_size
def accuracy(self,x,t):
y=self.predict(x)
y=np.argmax(y,axis=1)
t=np.argmax(t,axis=1)
accuracy=np.sum(y==t)/float(x.shape[0])
return accuracy
def numerical_gradient(self,f,x):#求偏导
h=1e-4
grad=np.zeros_like(x)
tmp_val=np.zeros_like(x[0])
for idx in range(x.size):
tmp_val=x[idx]#初始值
x[idx]=tmp_val+h
fxh1=f(x)
x[idx]=tmp_val-h
fxh2=f(x)
grad[idx]=(fxh1-fxh2)/(2*h)
x[idx]=tmp_val#还原x
return grad
def ng(self,x,t):
f=lambda w:self.loss(x,t)
grads={}
grads['W1']=self.numerical_gradient(f,self.params['W1'])
grads['b1']=self.numerical_gradient(f,self.params['b1'])
grads['W2']=self.numerical_gradient(f,self.params['W2'])
grads['b2']=self.numerical_gradient(f,self.params['b2'])
return grads
net=Net(input_size=784,hidden_size=225,output_size=15)
x=np.random.rand(100,784)
y=net.predict(x)
t=np.random.rand(100,15)
grads=net.ng(x,t)
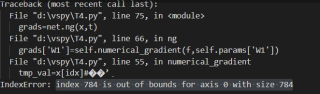
错误提示: