A文件
1 a 2013-04-01
1 a 2013-04-08
1 a 2013-04-28
2 a 2013-04-08
2 a 2013-11-11
3 a 2016-01-11
求MapReduce代码,实现以前两列为key,比较多个日期从中找出最早最晚时间,并统计出现次数, 如果时间只有一条记录,则最晚最早时间一样,都记录这个时间
B文件
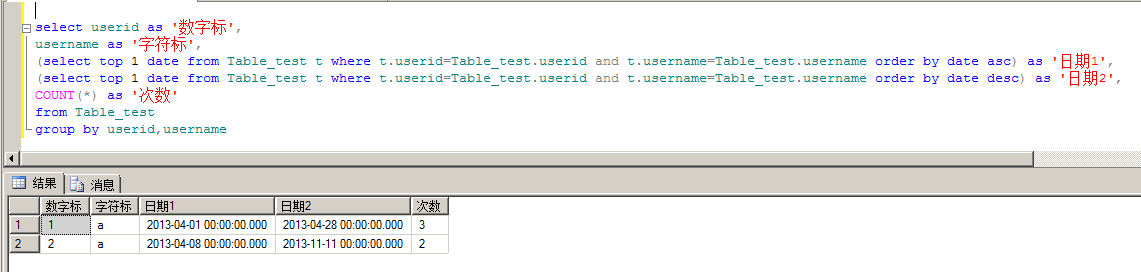
1 a 2013-04-01 2013-04-28 3
2 a 2013-04-08 2013-11-11 2
3 a 2016-01-11 2016-01-11 1

MapReduce 时间排序并统计

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2024-03-13 17:24通过MapReduce,这些算法可以在分布式环境中并行训练,加速模型构建,并利用大数据的力量提高预测准确性。 "ConcurrentToolsForSA-master"可能是一个包含用于并发分析的源代码或工具的项目,这可能包括定制的...
- 2016-10-23 10:51【大数据Hadoop MapReduce词频统计】 大数据处理是现代信息技术领域的一个重要概念,它涉及到海量数据的存储、管理和分析。Hadoop是Apache软件基金会开发的一个开源框架,专门用于处理和存储大规模数据集。Hadoop的...
- 2024-05-16 00:32Hadoop不仅包括MapReduce,还有HDFS(Hadoop Distributed File System),它是存储大数据的主要组件。数据首先被分布到HDFS的不同节点上,然后MapReduce框架在这些节点上并行运行Map和Reduce任务。 5. **Word ...
- 2024-04-21 15:20这个示例展示了如何创建一个简单的 MapReduce 程序,从输入文件中读取文本,统计每个单词出现的次数,并将结果写入输出文件。通过这种方式,用户可以理解 MapReduce 的基本原理及其在实际应用中的使用方法。
- 2025-09-16 03:54AI大模型应用之禅的博客 我们生活在一个“数据爆炸”的时代...MapReduce的诞生,就是为了解决“大数据如何分布式处理”的问题。用生活故事讲清楚MapReduce的核心逻辑;用代码示例演示MapReduce的具体操作;用企业实战说明MapReduce的真实应用;
- 2022-03-09 11:25在Reduce阶段,Map的输出被收集并按照key排序,然后传递给Reduce函数。Reduce函数负责聚合相同key的value,对计数值求和,最终输出每个单词的总数。这个过程展示了MapReduce的并行处理能力,使得大规模数据的统计变...
- 2024-11-06 22:56MapReduce是一种大数据计算架构,广泛应用于分布式数据处理领域,尤其是在处理大规模数据集时。它的核心思想是通过“Map(映射)”和“Reduce(归约)”两个操作来简化对大规模数据集的计算。该框架首先由Google提出...
- 2024-12-14 10:15MapReduce是一种编程模型,用于大规模数据集(大数据)的并行运算。其核心思想是通过将计算任务分解为两个阶段,即Map阶段和Reduce阶段来简化分布式计算过程。在MapReduce框架中,开发者需要编写Map函数和Reduce函数...
- 2024-12-22 11:24wertuiop_的博客 MapReduce是Google公司开源的一项重要技术,它提供了一种编程模型,用于处理和生成大数据集。MapReduce采用“分而治之”的思想,将大规模数据集的操作分发给一个主节点管理下的各个子节点共同完成,然后整合各个子...
- 2024-12-14 06:03大数据开发指南:MapReduce基础实战 MapReduce是一种编程模型,用于处理大规模数据集的并行运算。它由Google公司提出,并由Apache开源社区开发实现为Hadoop的一个重要组件。MapReduce模型的设计理念在于“分而治之...
- 没有解决我的问题, 去提问

