请教:从HDFS里读一个文件,map开拿出数据,转换成dataframe类型,再放入phoenix里面。转换成dataframe后,为什么给数据自动加一个前缀"_1","_2"。这样导致数据放入phoenix的时候,列簇对应不上,phoenix表已经创建好,定义过列簇名,下面是代码,和报错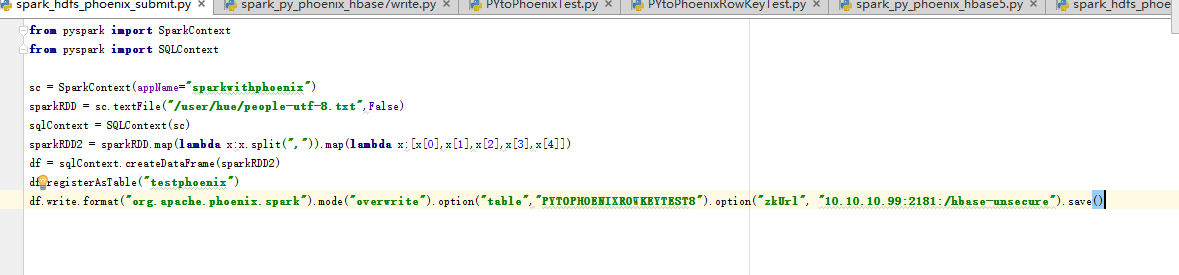
我创建phoenix表的行键列簇名字已经定义好了:HANGJIAN , LIECU ,LIECU2 ,LEICU5 ,HANGJIAN5
spark转换rdd的时候自动添加了"_1", "_2","_3"' "_4", "_5"
能不能转换数据的时候 ,不自动 加: _1 _2 等等前缀,直接让数据存入phoenix表中。请问大神们是怎么做的?

spark创建dataframe导入phoenix如何禁止自动创建字段编号

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答
- liu312018859 2016-02-24 02:06关注
问题搞定了
df = sqlContext.createDataFrame(sparkRDD2,["HANGJIAN","LIECU","LIECU2","LIECU5","HANGJIAN5"])
这是官网的from pyspark.sql import Row
Person = Row('name', 'age')
person = rdd.map(lambda r: Person(*r))
df2 = sqlContext.createDataFrame(person)
df2.collect()
[Row(name=u'Alice', age=1)]本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2016-02-23 08:03回答 2 已采纳 问题搞定了 df = sqlContext.createDataFrame(sparkRDD2,["HANGJIAN","LIECU","LIECU2","LIECU5","HANGJIAN5"])
- 2023-03-27 15:02回答 2 已采纳 我试着回答一下: 这个错误的原因是因为 employeeRDD 是一个包含字符串的 RDD,当使用 createDataFrame() 函数创建 DataFrame 时,Spark 无法将字符串转换为
- 2022-05-09 10:21回答 1 已采纳 你说啥问题
- 2021-08-28 09:59小基基o_O的博客 Phoenix建表 依赖 写 HBaseConfiguration.create 读 phoenixTableAsDataFrame
- 2022-12-22 18:36回答 2 已采纳 一、你要把‘Date’设置为索引df.set_index('Date',inplace=True)二、要把时间戳转换为数据中的日期时间对象df = df.rename(index=pd.Timesta
- 2017-09-22 03:23回答 2 已采纳 可能是scala驱动版本不匹配
- 2022-03-21 21:13回答 2 已采纳 没太明白你的意思,数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。数据帧(DataFrame)的功能特点:潜在的列是不同的类型大小可变标记轴(行和列)可以对行和列执行算术运算
- 2019-07-18 00:00王知无(import_bigdata)的博客 DataFrame 将数据写入hive中时,默认的是hive默认数据库,insert into没有指定数据库的参数,数据写入hive表或者hive表分区中:1、将Data...
- 2021-01-14 00:46回答 1 已采纳 import itertools site=['s1','s2'] t=[1,2,3,4] df = pd.DataFrame(columns={'site','t'}) for combinatio
- 2023-03-02 09:49回答 2 已采纳 df[df['date'].apply(lambda x: x.strftime('%m%d')) == '1231']
- 2022-05-10 20:05回答 1 已采纳 import pandas as pd dic1={'id':['862','8844','7890'],'keywords':[[{'id':931,'name':'jealousy'},{
- 2022-07-22 08:29讲文明的喜羊羊拒绝pua的博客 我们常见的大数据 SQL 解析都用到了这个工具,包括 Hive、Cassandra、Phoenix、Pig 以及 presto 等。 目前最新版本的 Spark 使用的是ANTLR4,通过这个对 SQL 进行词法分析并构建语法树。 可以通过github去查看spark...
- 2023-04-24 12:18回答 1 已采纳 参考CHATGPT和自己的理解回答,希望能帮到你使用Spark时遇到了一个数据类型不支持的问题。您正在尝试使用bigint(20)数据类型,但是出现了异常,提示该数据类型不受支持。 Spark SQL
- 2020-10-26 16:09Michael312917的博客 apache-phoenix-5.0.0-HBase-2.0安装与简单使用 HBase版本:hbase-2.0.5 官网地址:https://hbase.apache.org/ Phoenix版本:phoenix-5.0.0-HBase-2.0 Phoenix官网地址:http://phoenix.apache.org/download.html ...
- 2020-11-18 11:03蜂蜜柚子加苦茶的博客 Spark SQL精华及与Hive的集成SQL on HadoopSpark SQL前身Spark SQL架构Spark SQL运行原理Catalyst优化器(一)Catalyst优化器(二)Catalyst优化器(三)Spark SQL API(一)Spark SQL API(二)Spark SQL API(三)...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 解决一个加好友限制问题 或者有好的方案
- ¥15 关于#java#的问题,请各位专家解答!
- ¥15 急matlab编程仿真二阶震荡系统
- ¥20 TEC-9的数据通路实验
- ¥15 ue5 .3之前好好的现在只要是激活关卡就会崩溃
- ¥50 MATLAB实现圆柱体容器内球形颗粒堆积
- ¥15 python如何将动态的多个子列表,拼接后进行集合的交集
- ¥20 vitis-ai量化基于pytorch框架下的yolov5模型
- ¥15 如何实现H5在QQ平台上的二次分享卡片效果?
- ¥30 求解达问题(有红包)