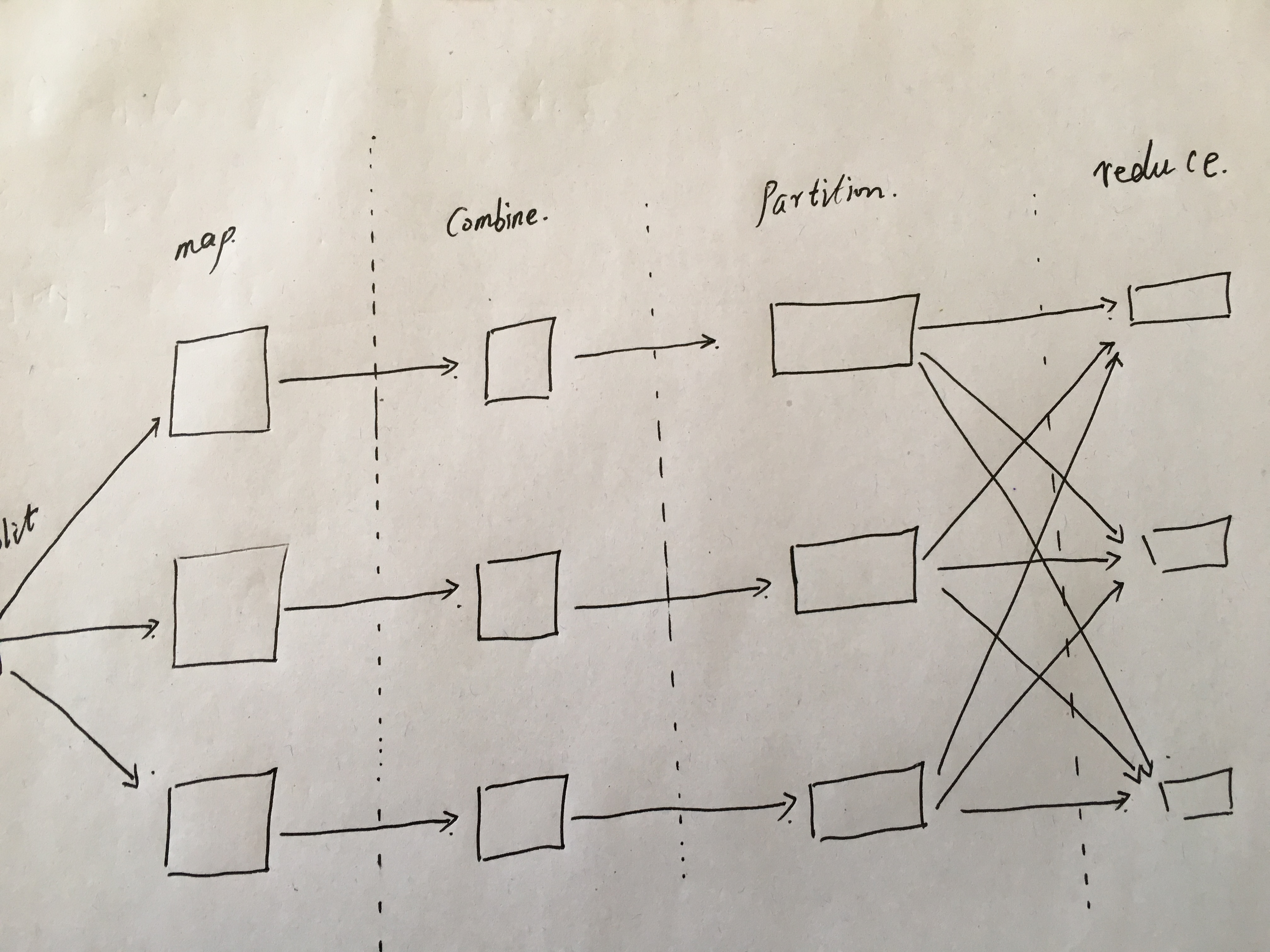
 这是我理解的hadoop函数调用过程,但还是有点疑惑,比如:每个map函数输出都调用一个partition函数(图中为此方式)还是一个partition函数处理所有的map输出,如果图中的过程正确,那么shuffle函数调用发生在哪里?
这是我理解的hadoop函数调用过程,但还是有点疑惑,比如:每个map函数输出都调用一个partition函数(图中为此方式)还是一个partition函数处理所有的map输出,如果图中的过程正确,那么shuffle函数调用发生在哪里?

hadoop中combine,partition和shuffle的疑问

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2016-03-08 04:31回答 2 已采纳 http://dongxicheng.org/mapreduce/hadoop-shuffle-phase/
- 2022-06-23 13:55回答 1 已采纳 Hadoop和Spark都是处理大数据的框架。就象你说关系型数据库,这只是一个概念,但是代表了一系列的含意,比如数据是结构化的,基于关系模型存储的。而MySQL、Oracle、SqlServer这些就
- 2022-12-19 16:44回答 1 已采纳 format只需要对NameNode做,如果你在node3做了也没关系,删除node3上的、hdfs-site.xml中配置的NameNode对应的目录即可,然后在node1上也删除相同的目录后,重新
- 2019-04-03 09:59灵佑666的博客 InputFormat类:该类的作用是将输入的文件和数据分割成许多小的split文件,并将split的每个行通过LineRecorderReader解析成<Key,Value>,通过job.setInputFromatClass()函数来设置,默认的情况为类...
- 2022-12-24 10:29回答 1 已采纳 Hadoop是一个分布式计算框架,可以在大数据集上运行分布式应用程序。它由许多组件组成,包括HDFS(分布式文件系统)和MapReduce(分布式计算引擎)。Hive是一个基于Hadoop的数据仓库系
- 2022-04-20 08:36回答 3 已采纳 排查方向:1、检查host文件,看IP地址跟主机名对应关系2、检查防火墙,需要关闭3、在这一步,即使你做了ssh免密登录,排查方向还是在ssh这里,主要是检查node23节点有没有把公钥传输到你的ma
- 2022-12-23 16:57回答 2 已采纳 集群还在启动吧,还是在安全模式,无法创建文件夹,稍等一会儿集群完全启动成功后就可以了。
- 2018-05-15 17:20爱萨萨的博客 InputFormat类:该类的作用是将输入的文件和数据分割成许多小的split文件,并将split的每个行通过LineRecorderReader解析成<Key,Value>,通过job.setInputFromatClass()函数来设置,默认的情况为类...
- 2023-03-02 16:06回答 3 已采纳 小魔女参考了bing和GPT部分内容调写:要安装配置Hadoop的完全分布式,首先需要准备好master节点和slave节点,其中master节点需要安装jdk,slave节点只需要安装ssh服务,并
- 2016-06-12 05:52回答 2 已采纳 你好 本人刚在大数据库处理方面 学习 对此有以下理解 1,大数据处理看到的注重点是对数据处理 ,字段与字段在oracle与oracle ,oracle与mysql,oracle与mariadb等数据
- 2021-11-09 17:48回答 1 已采纳 有可能datanode有多处磁盘损坏了,你可以尝试关闭其中那个有问题的节点继续测试
- 2021-08-21 11:24「已注销」的博客 1.4、Combiner合并 1.4.1、概述 1.4.2、自定义Combiner步骤 1.4.3、Combiner案例 总结 前言 前面MapReduce工作流程中的数据输入阶段InputFormat和切片机制,那么接下来就是中间的shuffle过程,shuffle机制 一、...
- 2022-10-26 11:41回答 1 已采纳 (1)Hadoop 1.0Hadoop 1.0即第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,Ma
- 2023-04-18 20:30化身孤岛的鲸o的博客 大数据开发学习总结——Hadoop
- 2023-05-13 14:38远道可思的博客 Hadoop是一个开源分布式计算平台架构,基于apache(阿帕奇)协议发布,由java语言开发。主要包括运行模式:单机版、伪分布式模式、完全分布式模式
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 程序不包含适用于入口点的静态Main方法
- ¥15 素材场景中光线烘焙后灯光失效
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记