请大神帮忙解决一下:六台机器,SparkStreaming的例子程序,运行在yarn上四个计算节点(nodemanager),每台8G内存,i7处理器,想测测性能。
自己写了socket一直向一个端口发送数据,spark 接收并处理
运行十几分钟汇报错:WARN scheduler TaskSetManagerost task 0.1 in stage 265.0 :java.lang.Exception:Could not compute split ,block input-0-145887651600 not found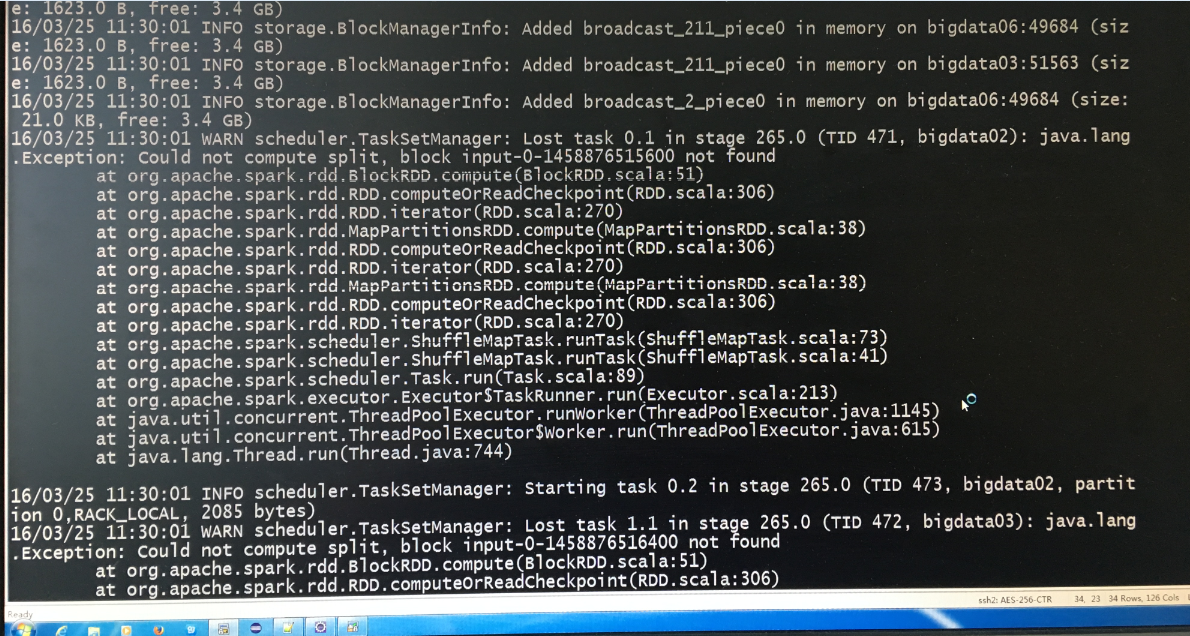

六台机器集群,40M数据就报错,spark streaming运行例子程序wordcount

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


0条回答
- 2022-04-04 22:57回答 2 已采纳 本地执行需要去掉,依赖范围provided,可以查看我的微博,flink专栏
- 2022-11-08 20:23回答 1 已采纳 看下是不是还有报错classNotFoundException.应该是你导入包的时候补全 少了AvroSourceProtocol相关包或者是版本依赖错了.首先看下这个类是那个jar里面的,然后再分
- 2017-08-04 10:06回答 1 已采纳 http://blog.csdn.net/svmachine/article/details/52200761
- 2022-03-27 15:08技匠三石弟弟的博客 从TCP Socket数据源实时消费数据,对每批次Batch数据进行词频统计WordCount,流程图如下: 二、准备工作 本地使用nc命令,利用它向8888端口发送数据(备注:nc是netcat的简称,原本是设置路由器),输入命令如下...
- 2022-08-22 12:13回答 2 已采纳 EGLSink改为以下:sink = Gst.ElementFactory.make("fakesink", "fakesink")
- 2023-01-23 19:40回答 2 已采纳 看起来你好像少这个jar : kafka-clients,查找一下项目里引用了没有 另外就是需要你check一下你代码里是否使用了 StringDeserializer 代替了 StringSer
- 2022-11-11 14:34回答 1 已采纳 我觉得你可能日志定位错了,看逻辑应该只有去重算子有状态会造成CK超时状态过大崩溃重启,重启之后逻辑就类似你这个日志
- 2018-09-13 20:57桃花惜春风的博客 关于Spark-Streaming官方示例: https://github.com/apache/spark/tree/master/examples 本文采用kafka作为spark输入源 运行时出现以下日志: 18/09/12 11:15:28 INFO JobScheduler: Added jobs ...
- 2023-01-17 10:39回答 3 已采纳 这个是github上个人维护的spark-aql勾子程序,你的问题应该是设置高版本的spark和scala,造成了一些版本冲突,而且高版本中许多类都更新过了,当然找不到.(1)<import o
- 2021-10-25 15:00回答 2 已采纳 你好,我是有问必答小助手,非常抱歉,本次您提出的有问必答问题,技术专家团超时未为您做出解答本次提问扣除的有问必答次数,将会以问答VIP体验卡(1次有问必答机会、商城购买实体图书享受95折优惠)的形式为
- 2015-06-15 09:01回答 1 已采纳 问题已 解决。。。 allData 加上cache之后异常可以解决了,这是为什么呢? 其中又出现了一个错误: 

悬赏问题
- ¥15 php 同步电商平台多个店铺增量订单和订单状态
- ¥15 关于logstash转发日志时发生的部分内容丢失问题
- ¥17 pro*C预编译“闪回查询”报错SCN不能识别
- ¥15 微信会员卡接入微信支付商户号收款
- ¥15 如何获取烟草零售终端数据
- ¥15 数学建模招标中位数问题
- ¥15 phython路径名过长报错 不知道什么问题
- ¥15 深度学习中模型转换该怎么实现
- ¥15 Stata外部命令安装问题求帮助!
- ¥15 从键盘随机输入A-H中的一串字符串,用七段数码管方法进行绘制。提交代码及运行截图。