我最近考研需要这个网站的视频,想用python爬下来。
这个网站的请求视频的地址好像是用代码生成的,而且需要手动点击才能抓到,抓包一个一个来好慢啊!!
后来发现这个网站的flash播放器的预览图地址和视频请求地址很相似,可是虽然这个预览图是默认加载的,可不过也只能在chrome的抓包里看到这个单独页面请求地址
最关键的问题还是这里的地址没有规律,地址有两个参数(图里面显示出来的那一段),有一个死活找不出来,求大神帮忙分析一下源代码,找出来这个地址的生成方法
如果有人能够有别的爬取的方法也可以的啊
网页地址:http://mooc.chaoxing.com/nodedetailcontroller/visitnodedetail?knowledgeId=757531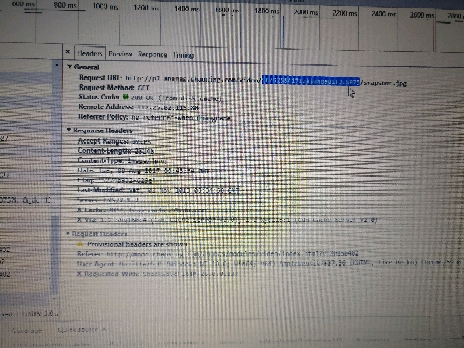

爬虫好难啊,求网页源代码分析,助考研一臂之力

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
- 2015-08-11 04:55回答 5 已采纳 代码: ``` #!/usr/bin/env python3 #-*- coding=utf-8 -*- import urllib3 if __name__ == '
- 2023-04-13 13:18回答 1 已采纳 爬虫严格来讲并不算一个大方向,更偏向于js逆向,python的话推荐走后端方向至于系统学习的话,推荐去blibili找一些路线,然后根据路线去找bilibili上播放量比较高的视频进行系统学习
- 2018-12-13 14:2381个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
- 2021-09-11 12:34回答 1 已采纳 看到上面的onclick了吗,点击的时候,会执行js,然后通过js代码访问了新的链接
- 2022-02-24 11:15回答 2 已采纳 那个网站啊.你看下是不是写在接口中.F12开发者模式.选择XHR看下
- 2021-07-27 10:11回答 2 已采纳 Class spd'定义爬虫类 Public url as String'定义url Sub sp()'定义方法 With CreateObject("Microsoft.XMLHTTP") .Ope
- 2022-03-05 22:13爬取淘宝商品数据项目的源代码
- 2023-01-07 20:57回答 1 已采纳 是不是通过xpath爬取时,没有找到对应的元素,定位的表达式怎么写的?
- 2018-10-16 03:13回答 1 已采纳 你打开的第一页,其实在你往下划的时候网页加载了XHR,所以你使用seleniem也需要模拟下滑 ``` driver.execute_script("window.scrollBy(0,5
- 2022-10-26 16:35回答 1 已采纳 post和get方法的使用不是你决定的,二十接口使用的是什么请求方式,如果它是get请求那就只能用get请求,是post就只能用post
- 2019-02-26 10:27xiucai_cs的博客 # 获取网页源代码 kv = {'user-agent':'Mozilla/5.0'} # 请求头信息,相当于一个浏览器面具 html = requests.get('http://tieba.baidu.com/f?ie=utf-8&kw=python&red_tag=g1015520224',headers=kv) ...
- 2021-10-31 23:19回答 1 已采纳 beautifulsoup是爬静态网页的,应该是有些内容属于动态,可以尝试selenium
- 2022-01-11 19:52滚雪球~的博客 通过如下代码,会发现获取的网页源代码出现乱码 url = 'https://www.baidu.com' res = requests.get(url).text print(res) 出现乱码 查看python获得的编码格式 import requests # 0.通过如下代码,会发现获取的...
- 2021-09-14 15:27AI悦创|编程1v1的博客 很多同学一听到 Python 或编程语言,可能条件反射就会觉得“很难”。但今天的 Python 课程是个例外,因为今天讲的 **Python 技能,不需要你懂计算机原理,也不需要你理解复杂的编程模式。**即使是非开发人员,只要...
- 没有解决我的问题, 去提问



](http://mooc.chaoxing.com/nodedetailcontroller/visitnodedetail?knowledgeId=757531!%5B%E5%9B%BE%E7%89%87%5D(https://img-ask.csdn.net/upload/201708/08/1502190679_257869.jpg)){kind=link}