python爬虫爬取网页源码,返回结果是网页源代码,而我要元素里的代码,因为我需要的东西源代码没有
先分享一下代码和运行结果:


我最终需要的是这个网址

也就是这个元素代码
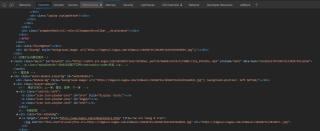
但是它返回的是源代码,与元素不同,所以我之后用beautifulsoup爬不到这个网址
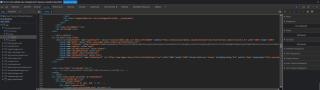
(大家可以以那个html注释 “flash播放控件” 来定位代码哦)
这个问题我遇到已经很久了,我搜了好长时间也没找到比较好的解决方法(或是看不懂),请各位懂得帮忙指点一下,谢谢( ̄︶ ̄*))

python爬虫爬取网页源码,返回结果是网页源代码,而我要元素里的代码,因为我需要的东西源代码没有
先分享一下代码和运行结果:
我最终需要的是这个网址
也就是这个元素代码
但是它返回的是源代码,与元素不同,所以我之后用beautifulsoup爬不到这个网址
(大家可以以那个html注释 “flash播放控件” 来定位代码哦)
这个问题我遇到已经很久了,我搜了好长时间也没找到比较好的解决方法(或是看不懂),请各位懂得帮忙指点一下,谢谢( ̄︶ ̄*))
 分享
分享
因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
分享 系统已结题
8月25日
系统已结题
8月25日 已采纳回答
8月17日
创建了问题
8月17日
已采纳回答
8月17日
创建了问题
8月17日


