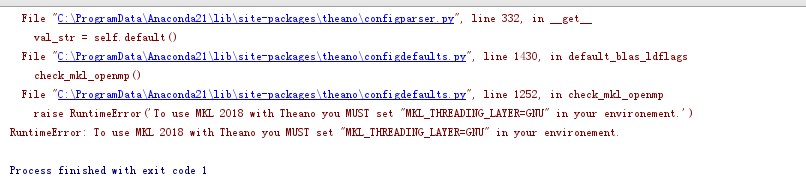
keras 后端:theano

python 运行错误希望有大神帮忙。

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2022-02-08 09:42回答 3 已采纳 将谷歌浏览器驱动直接放在你python 的安装目录即可,如图 如果对你有帮助,可以点击我这个回答右上方的【采纳】按钮,给我个采纳吗,谢谢
- 2017-09-12 09:44回答 2 已采纳 找不到原因,我改成 "hello-exchange", "direct", False, True, False 后可以使用, 把变量去掉了
- 2017-06-25 08:05回答 5 已采纳 ``` def chaxun(CTname): //函数参数数目为1,调用时,传了2个参数,不匹配。 ```
- 2020-11-20 19:40weixin_39542093的博客 Python 方向岗位的薪水在水涨船高,成为目前最有潜力的编程语言之一。1.《“笨办法”学Python(第3版)》尽享5小时的完整视频教程,跟着数十万人的Python导师学Python编程入门基础教程,为Web开发实战数据分析打下坚实...
- 2017-04-18 04:56回答 1 已采纳 ``` pip install tornado==4.4.3 ```
- 2016-12-20 04:17回答 2 已采纳 http://blog.csdn.net/kinglearnjava/article/details/49107253
- 2015-10-17 12:04回答 4 已采纳 在CSDN下载中找到pysqlite-2.6.3.win32-py2.7的exe安装包. 下载地址下面有, 然后因为是32位的包,所以需要修改注册表才可以安装具体如下文. Python的一些第三
- 2020-11-23 19:06weixin_39624700的博客 初始化时使用PYTHONPATH环境变量的值10 11 sys.platform 返回操作系统平台名称12 13 sys.stdin 输入相关14 15 sys.stdout 输出相关16 17 sys.stderror 错误相关 sys基本知识 1 importsys2 importtime3 4 5 defview_...
- 2021-01-21 19:54回答 2 已采纳 elif等语句要紧跟上一行语句,并顶格写。
- 2023-01-19 20:38回答 2 已采纳 你的python版本是多少?目前pygame正式版只支持到python3.9
- 2021-03-19 15:43回答 2 已采纳 不需要那么复杂,一句就行。df['idno_bz'] = df['idno'].map(lambda x: 'gf' if x==18 else 'no_gf' )
- 2020-12-17 21:25weixin_39719077的博客 packages\pywifi\__init__.py", line 15, in from .wifi import PyWiFi File "C:\Users\Administrator\AppData\Local\Programs\Python\Python37-32\lib\site-packages\pywifi\wifi.py", line 15, in from .iface ...
- 2022-02-02 19:44回答 2 已采纳 要使用多线程实现多个任务,具体可以参考:https://www.cnblogs.com/fnng/p/3670789.html
- 2020-11-20 22:47weixin_39948824的博客 我已经编写了一些代码来尝试执行以下操作 我之前在python代码中检索过的opensvg文件查看文件中的特定正则表达式(r“(?:xlink:href = ”)(。*)(?:?q = 80“>)”) 如果找到匹配项,请将文本替换为...
- 2024-04-14 21:23Merl520的博客 如图所示,在网上下了个批量发邮件的模板,点击发送就显示错误429,不能创建对象,求大神帮忙看一下,要怎么解决,万分感谢!
- 没有解决我的问题, 去提问

