hello,各位大神好,我导入一个CSV文件,有8列,如图。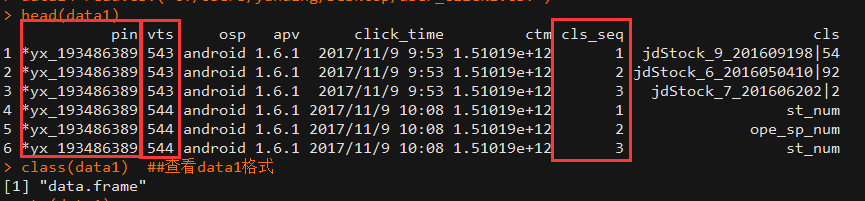
我想按PIN列及vts列作为分组依据,以cls_seq作为统计依据求cls_seq列的较大值。
代码如下
data1<-read.csv("C:/**/**/Desktop/user_click1.csv")head(data1)
class(data1) ##查看data1属性
str(data1) ##查看data1列属性
max_seq<- aggregate(data1[7],data1[1:2],max) ##分组求较大值
head(max_seq) ##输出max_seq前6行
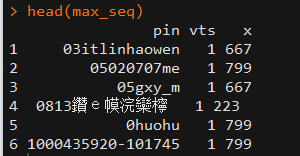
我觉得答案应该是分组及较大值,如
pin vts cls_seq
*yx_193486389 543 3
*yx_193486389 544 3
但是结果如下图 ,我查过所有数据,cls_seq较大不超过100,可是我的max 列中大部分数据都是好几百,请问是怎么回事,该怎么修改,谢谢各位大神。