我自已写的日志,中文输出正常,scrapy框架自动生成的日志记录,中文输出是一串字符串,怎么输出为中文?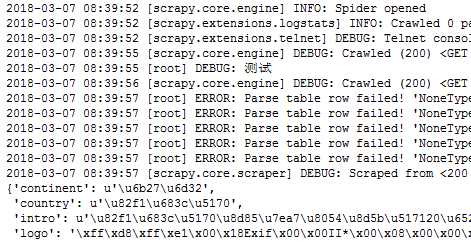

scrapy - 怎么让scrapy框架产生的日志输出中文

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 u010088895 2018-03-07 01:37关注
u010088895 2018-03-07 01:37关注scrapy框架用的少,但是以前在用别的框架的时候,要把底层的输出改成中文,进行所谓的“国际化”操作。但是那个还得自己去写exception对应的中文。
解决 无用评论 打赏举报 分享
- 2020-09-01 19:12回答 2 已采纳 ``` browser.quit() return HtmlResponse(url=request.url, body=browser.page_source, re
- 2019-06-14 18:44回答 3 已采纳 直接源码安装redis就可以了, 其他的都不用安装的呀
- 2022-05-06 00:26回答 2 已采纳 你应该继承 scrapy.SpiderCrawlSpider 不要自定义 parse 函数。
- 2023-02-22 12:23向岸看的博客 与scrapy框架不同的是,scrapy-redis框架中request链接不再交付于调度器(Scheduler)中url队列,而是保存在redis数据库中,再由过滤器进行过滤,符合要求的请求链接再交付于调度器(Scheduler),此外redis数据还...
- 2022-09-12 18:54回答 2 已采纳 结果是什么
- 2021-04-02 17:02回答 3 已采纳 # 导入所需库 import requests class Jdcomment_spider(object): # 请求头 headers = { 'User-A
- 2020-05-09 18:12回答 3 已采纳 如图:如果你完整的看完scrapy的日志(第一张图),根本原因:你设置了robotstxt服从为真,直接原因:目标网站的robot限制了你的访问
- 2019-05-05 10:57Harrytsz的博客 scrapy-redis分布式爬虫框架详解 随着互联网技术的发展与应用的普及,网络作为信息的载体,已经成为社会大众参与社会生活的一种重要信息渠道。由于互联网是开放的,每个人都可以在网络上发表信息,内容涉及各个方面...
- 2021-09-04 13:52回答 1 已采纳 检查一下哪个python.exe执行的这个文件,找到python的完整路径,比如c:\python39\python.exe然后执行 c:\python39\python.exe -c "import
- 2020-03-25 14:18回答 1 已采纳 def parse(self, response): result = eval(response.body.decode('utf-8')) 兄弟,你打印一下resu
- 2021-06-26 13:47回答 1 已采纳 这是一个JSON数组,JSON里面不能空行,否则转换可能会出问题。
- 2020-06-20 23:03wutongheihei666的博客 scrapy_redis是scrapy框架的基于redis的分布式组件 3. scrapy_redis的作用 Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在: 通过持久化请求队列和请求的指纹集合来实现: 断点续爬 分布式...
- 2018-07-11 12:56回答 1 已采纳 I finally found how to do so, I am sure this is not the best way but at least I did what I wanted
- 2022-03-07 09:34CodeJiao的博客 Python爬虫 scrapy -- scrapy 日志信息和日志等级、scrapy shell的使用、scrapy post请求
- 2022-04-27 12:14办公模板库 素材蛙的博客 了解 scrapy框架的作用 掌握 scrapy框架的运行流程 掌握 scrapy中每个模块的作用 1. scrapy的概念 Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。 Scrapy ...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 素材场景中光线烘焙后灯光失效
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记
- ¥15 保护模式-系统加载-段寄存器