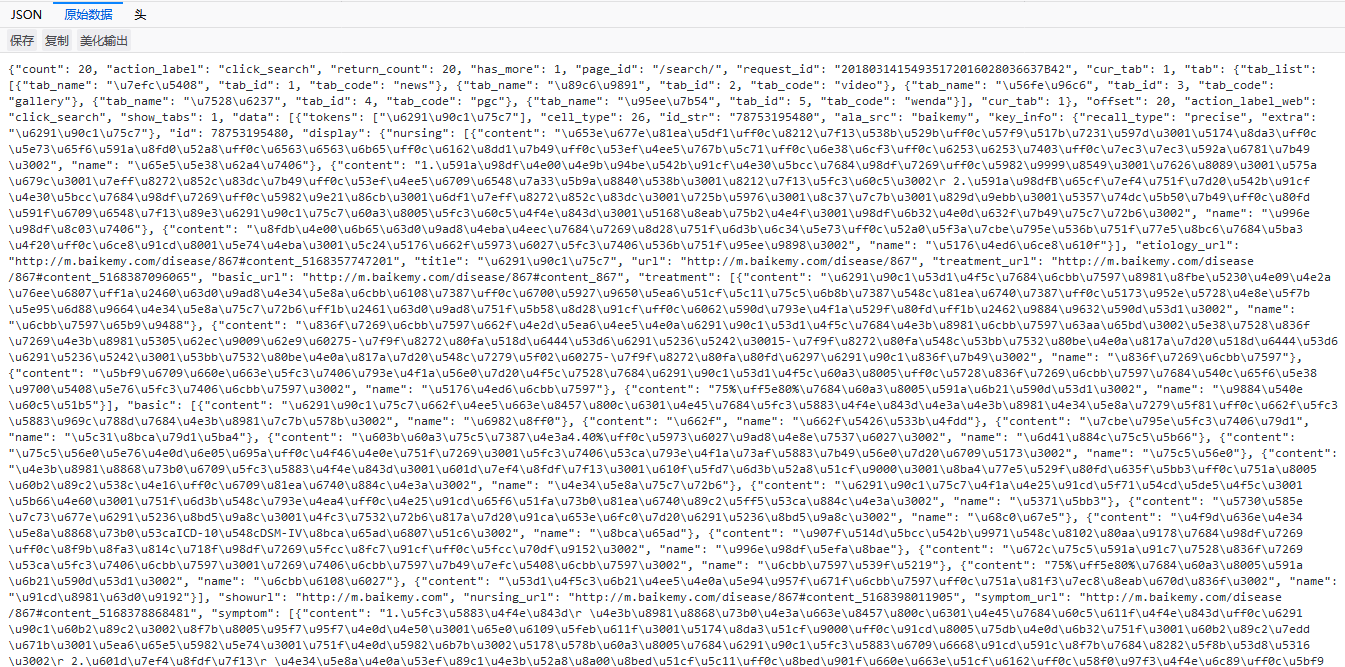
 最近在做scrapy爬虫,发现有的网页好像需要爬json。我跟踪到了这个json文件,那么请问怎么爬取我需要的数据呢?xpath我理解了,但是json的数据不是很会啊。。
最近在做scrapy爬虫,发现有的网页好像需要爬json。我跟踪到了这个json文件,那么请问怎么爬取我需要的数据呢?xpath我理解了,但是json的数据不是很会啊。。
PS.简单来说就是怎么样把这些json的数据转化为xpath的地址啊?

scrapy爬虫相关 关于json数据的处理

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 摆码王子 2018-03-14 10:27关注
摆码王子 2018-03-14 10:27关注使用 JSON 函数需要导入 json 库:import json
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2024-01-03 01:46在这个项目中,Flask被用作前端展示平台,接收来自Scrapy爬虫的数据并以用户友好的方式展示。开发人员可能创建了路由来处理HTTP请求,定义了视图函数来返回HTML模板,这些模板中可能嵌入了爬取到的IMDb数据,让用户...
- 2021-02-01 17:33Mr数据杨的博客 通过这些内容,你已经了解了如何灵活地选择和配置不同的序列化格式、存储方式,以及如何通过数据过滤和提交处理来确保数据的质量和可用性。掌握这些技能后,你将能够根据具体的项目需求,自如地调整和优化数据输出...
- 2024-09-26 10:45豆包程序员的博客 歌曲标签搜索:用户可以通过不同的音乐标签搜索相关歌曲,如流派、心情、语言等。音乐评分管理:用户可以为歌曲打分,并查看歌曲的平均评分。排行榜:展示各类排行榜,包括按照播放量、下载量和评分的排行。热门推荐...
- 2020-12-16 23:58在本文中,我们将探讨如何使用Django和Scrapy框架结合来生成后端JSON接口。...4. 编写Scrapy爬虫逻辑,提取和解析JSON数据。 5. 定义Pipeline保存数据到Django数据库。 6. 创建Django视图或API接口提供数据给前端。
- 2025-05-11 15:20大雨淅淅的博客 Scrapy是一个强大的应用框架,能轻松实现数据的高效抓取和处理;BeautifulSoup擅长解析 HTML 和 XML 文档,方便提取网页中的数据;Selenium则可以模拟浏览器操作,解决一些需要交互才能获取数据的场景 。
- 2020-12-11 14:16xbhog的博客 Django-Scrapy生成后端json接口: 网上的关于django-scrapy的介绍比较少,该博客只在本人查资料的过程中学习的,如果不对之处,希望指出改正; 以后的博客可能不会再出关于django相关的点; 人心太浮躁,个人深度...
- 2018-12-04 14:41cx羽的博客 Python 后端爬虫Scrapy 框架使用:
- 2024-07-01 16:41K哥爬虫的博客 它提供了简单易用的工具和组件,使开发者能够定义爬虫、调度请求、处理响应并存储提取的数据。Scrapy 具有高效的异步处理能力,支持分布式爬取,通过其中间件和扩展机制可以方便地定制和扩展功能,广泛应用于数据...
- 2024-07-21 14:00月流霜的博客 当你写了很多个爬虫程序之后,你会发现每次写爬虫程序时,都需要将页面获取、页面解析、爬虫调度、异常处理...Scrapy 是基于 Python 的一个非常流行的网络爬虫框架,可以用来抓取 Web 站点并从页面中提取结构化的数据。
- 2025-02-23 19:50QQ_402205496的博客 独立开发设计系统的模块程序,...基于Python大数据技术进行网络爬虫的设计,框架使用Scrapy.系统设计支持以下技术栈前端开发框架:vue.js数据库 mysql 版本不限后端语言框架支持:数据库工具:Navicat/SQLyog等都可以。
- 没有解决我的问题, 去提问

