关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
Autismdj
2018-04-09 03:37
采纳率: 0%
浏览 2102
首页
已结题
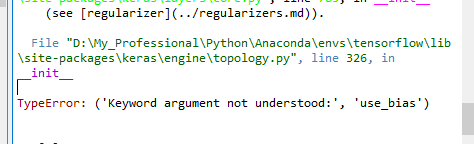
训练dnn网络,添加全连接层,keras报错
dnn
keras
更改了keras的版本号,依然报错
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
4
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
pangu5
2018-04-09 03:38
关注
添加全连接层 ? 对么
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(3条)
向“C知道”追问
报告相同问题?
提交
关注问题
keras
搭建全连接神经
网络
问题小记
2024-01-09 12:10
heusjh的博客
简要叙述了环境配置的思考;
网络
搭建、保存、加载的方法;以及一些小技巧和反思。以供初学者学习。
深度神经
网络
终极指南:从数学本质到工业级实现(附
Keras
版本代码)
2025-02-19 22:43
y江江江江的博客
(2)一种思路是在
训练
大型
网络
之前使用少量数据
训练
一个较小的模型,小模型的泛化好,再去
训练
更深、更大的
网络
。一个标准是精确率,也叫查准率,其公式是用“被模型预测为正的正样本”除以“被模型预测为正的正...
人工智能
AI:TensorFlow
Keras
PyTorch MXNet PaddlePaddle 深度学习实战 part1
2019-09-03 23:11
あずにゃん的博客
github标星11600+:最全的吴恩达机器学习课程资源(完整笔记、中英文字幕视频、python作业,提供百度云镜像!)
Keras
PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战 用户画像 C、C++笔记 JavaWeb+大数据...
DNN
(Deep-Learning Neural Network)
2021-04-15 10:32
sherlock31415931的博客
接下来介绍比较常见的
全连接层
网络
(fully-connected feedfoward nerural network) 名词解释 首先介绍一下神经
网络
的基本架构,以一个神经元为例 输入是一个向量,权重(weights)也是一个矩阵 把两个矩阵进行相乘...
开发小智AI黑客机器人并上传全云端
2024-06-29 21:27
小熙智菏——Sunspot的博客
与连接,以便能够尽快的理解和应用在黑客机器人与人类情感相互学习交流 相关文献: AI智能潜在威胁,黑客利用AI聊天机器人轻松入侵
网络
https://new.qq.com/rain/a/20230106A06VJ200 机器人黑客首次公开挑战人类,...
AI
人工智能
从入门到实战:完整教程
2025-12-30 11:34
BUG 饲养员的博客
本文系统介绍了
人工智能
(AI)从基础认知到实战开发的完整知识体系。
清华青年AI自强作业hw4:基于
DNN
实现狗狗二分类与梯度消失实验
2023-06-28 08:05
来知晓的博客
hw4总体分为part1/part3都是用全连接
网络
来进行狗狗图片二分类,区别只在于
网络
结构的差异。part2验证梯度小消失的问题。
【自然语言处理】2. Attention实现详细解析( tfa,
keras
方法调用源码分析 & 自建
网络
)
2021-08-20 22:02
striving长亮的博客
最近几年,Attention模型在NLP乃至深度学习、
人工智能
领域都是一个相当热门的词汇,被学术界和工业界的广大学者放入自己的模型当中,并得到了不错的反馈。再加上BERT的强势表现以及Transformer的霸榜,让大家对...
【DL】
网络
搭建及
训练
2022-10-05 09:42
Sonhhxg_柒的博客
6
网络
训练
有哪些技巧吗? 6.1.合适的数据集。 6.2.合适的预处理方法。 6.3.
网络
的初始化。 6.4.小规模数据试练。 6.5.设置合理Learning Rate。 6.6.损失函数 1 TensorFlow 1.1 TensorFlow是什么? TensorFlow...
[Python图像识别] 四十七.
Keras
深度学习构建CNN识别阿拉伯手写文字图像
2021-10-03 12:00
Eastmount的博客
该系列文章是讲解Python OpenCV图像处理知识,...本文主要通过
Keras
深度学习构建CNN模型识别阿拉伯手写文字图像,一篇非常经典的图像分类文字。本文参考并复现了刘润森老师的博客,推荐大家关注他的文章,真的非常棒!
在
KERAS
中构建多输出模型时出错
2024-10-07 07:09
潮易的博客
对于
人工智能
大模型方面的应用,例如在医疗健康领域的疾病检测中,每个输出的二分类问题可以分别代表疾病的某种特征或症状的预测。output1 = layers.Dense(1, activation='sigmoid', name='output1')(x) # 假设输出...
YOLOv8
网络
理解
2024-07-24 08:15
AI算法爱好者角落的博客
YOLOV8
网络
结构Yolov8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,主要借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,其本身创新点不多,偏重在工程实践上。YOLOv8的提出主要...
AI上推荐 之 MIND(动态路由与胶囊
网络
的奇光异彩)
2022-03-27 07:39
翻滚的小@强的博客
双塔模型等,都是把用户的基本信息,或者用户交互过的历史商品信息等,过一个
全连接层
,最后编码成一个向量,用这个向量来表示用户兴趣,但作者认为,这是多兴趣表示的瓶颈,因为需要压缩所有与用户多兴趣相关的信息...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
 关注
关注  微信扫一扫
微信扫一扫 分享
分享