
最近在弄这个算法时,发现网上的大多数教程对于 “从结果中去除用户已经评论过的数据”都只是提出,却没有实现,因此在最后推荐结果会出现用户已经评论过的数据。在自己实现时遇到了问题。以下step6是“从结果中去除用户已经评论过的数据”内容
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.commons.net.telnet.EchoOptionHandler;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.logaggregation.AggregatedLogFormat.LogWriter;
//获得结果矩阵
public class Step6 {
public static boolean run(Configuration con, Map<String, String>map) {
try {
FileSystem fs = FileSystem.get(con);
Job job = Job.getInstance();
job.setJobName("step6");
job.setJarByClass(App.class);
job.setMapperClass(Step6_Mapper.class);
job.setReducerClass(Step6_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,
new Path[] {
new Path(map.get("Step6Input1")),
new Path(map.get("Step6Input2"))
});
Path outpath = new Path(map.get("Step6Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
}catch(Exception e) {
e.printStackTrace();
}
return false;
}
static class Step6_Mapper extends Mapper<LongWritable, Text, Text, Text>{
private String flag;
//每次map时都会先判断一次
@Override
protected void setup(Context context )throws IOException,InterruptedException{
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
if(flag.equals("step5")) {
String userID = tokens[0];
Text itemID = new Text(tokens[1]);
//tokens[1] 物品id tokens[2] 用户对物品评分
Text v = new Text("A:"+userID+","+tokens[1]+","+tokens[2]);
//输出key为itemID
context.write(itemID, v);
}else if(flag.equals("step2")) {//用户评价矩阵
// u2 i1:2,i3:4
String userID = tokens[0];
for(int i=1;i<tokens.length;i++) {
String[] vector = tokens[i].split(":");
String itemID = vector[0]; //物品ID
// String pref = vector[1];//评分
Text k = new Text(itemID);
Text v = new Text("B:"+userID+","+itemID);
//输出key万为itemid
context.write(k, v);
}
}
}
}
static class Step6_Reducer extends Reducer<Text, Text, Text, Text>{
protected void reduce(Text key, Iterable<Text>values, Context context) throws IOException,InterruptedException{
//物品ID为map的key
Map<String, String> mapA = new HashMap<String,String>();
//该物品(key中的itemID)
Map<String, Integer>mapB = new HashMap<String,Integer>();
for(Text line : values) {
String val = line.toString();
if(val.startsWith("A:")) {
String[] kv = Pattern.compile("[\t,]").split(val.substring(2));
String userID = kv[0];//用户ID
String tokens = kv[2];//用户的对物品评分
String itemID = kv[1];//物品ID
mapA.put(userID, itemID+","+tokens);
}else if(val.startsWith("B:")) {
String[] kv = Pattern.compile("[\t,]").split(val.substring(2));
//kv[0] = userID
//kv[1] = itemID
//kv[2] = price
try {
mapB.put(kv[0], Integer.parseInt(kv[1]));
}catch(Exception e) {
e.printStackTrace();
}
}
}
Iterator<String> itera = mapA.keySet().iterator();
while(itera.hasNext()) {
String userID = itera.next();
String score = mapA.get(userID);
String[] kv = score.toString().split(",");
Text v = new Text(kv[0]+","+kv[1]);
Iterator<String>iterb = mapB.keySet().iterator();
while(iterb.hasNext()) {
String mapkb = iterb.next();//用户ID
String itemID = Integer.toString(mapB.get(mapkb));//物品ID
//Text k = new Text(mapkb);
//去除用户已评论过的数据
if(mapkb.equals(userID)&&itemID.equals(kv[0])) {
continue;
}else {
Text ke = new Text(mapkb);
context.write(ke, v);
}
}
}
}
}
其中step2的数据为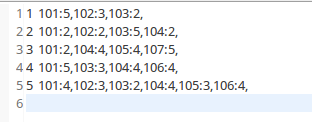
step5数据为
按照自己写的step6的输出数据为
显然数据中出现了许多重复数据。实在不了解怎么弄了,请各位提供个思路,或者帮看下哪里有问题。






