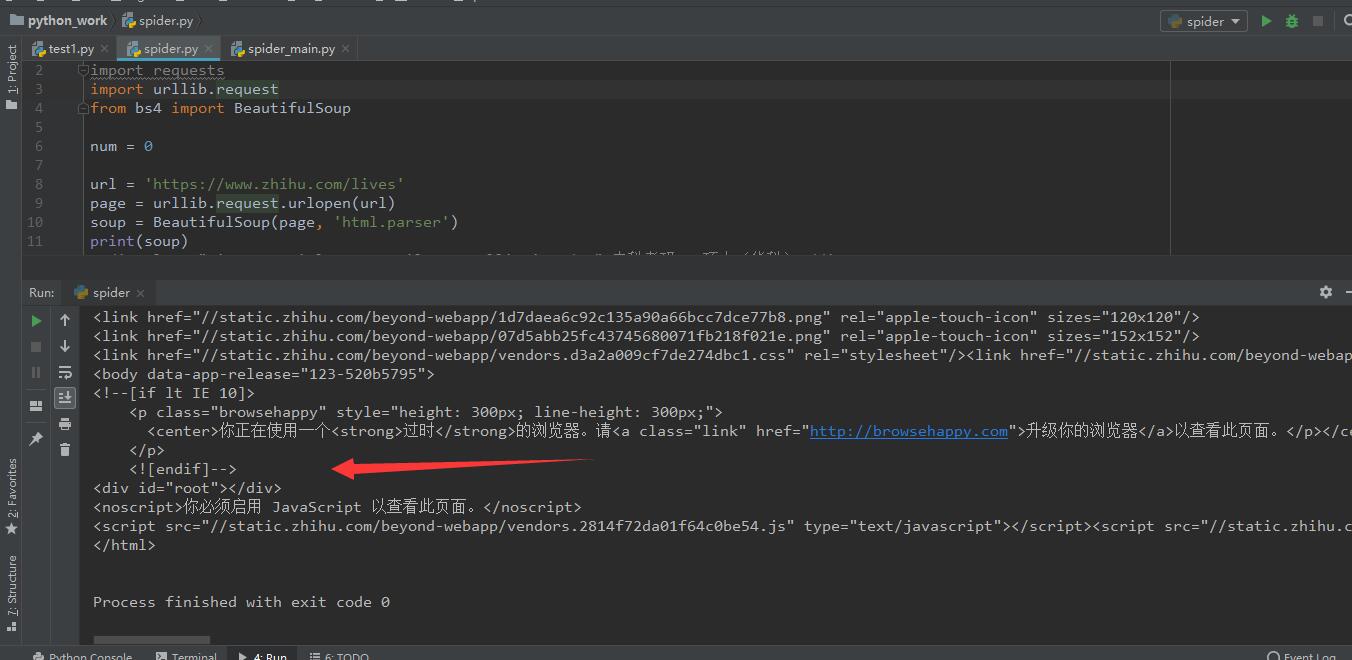
源码
#coding= gbk
import requests
import urllib.request
from bs4 import BeautifulSoup
num = 0
url = 'https://www.zhihu.com/lives'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
print(soup)
想爬取关于知乎live的一些内容,但是返回的网页源码div标签都未展开,也就无法搜索到文本内容,求教大佬!另外还问一下对于知乎这种要向下滑动才能显示更多的网页,要如何改写代码,读取更多的内容?