为什么我测试的text()和string()都可以获得子标签下的文本??后端也能正常获取到,面试的时候面试官说的我一脸懵逼。。。。。。因为我一直用的都是text去获取文本,一直也都能获取到,面试官说text不能获取子标签下的文本,只有string可以。。。
下图为斗鱼的直播页面,写了各种的格式测试text发现都能正常获取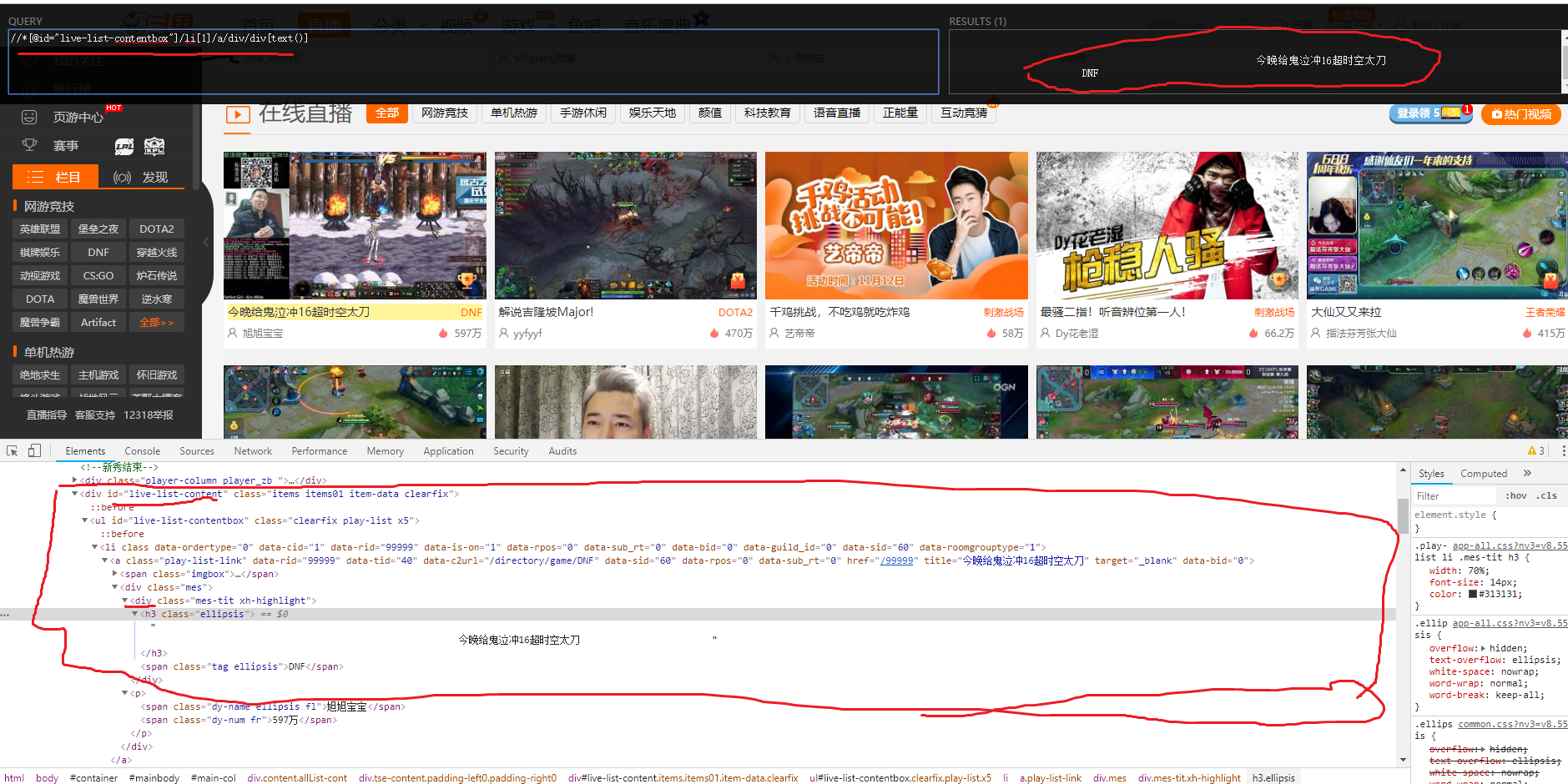
后端获取我也试了,也是可以获取到的。
求来个大佬来解答下,现在很困惑,面试也没过有点难受
最后:
许愿韩茜茜的流响

为什么我测试的text()和string()都可以获得子标签下的文本??后端也能正常获取到,面试的时候面试官说的我一脸懵逼。。。。。。因为我一直用的都是text去获取文本,一直也都能获取到,面试官说text不能获取子标签下的文本,只有string可以。。。
下图为斗鱼的直播页面,写了各种的格式测试text发现都能正常获取
后端获取我也试了,也是可以获取到的。
求来个大佬来解答下,现在很困惑,面试也没过有点难受
最后:
许愿韩茜茜的流响
 分享
分享



