request后json的值为空,这是什么情况,各位老师给看看,谢谢
还有怎么上传图啊,手机。
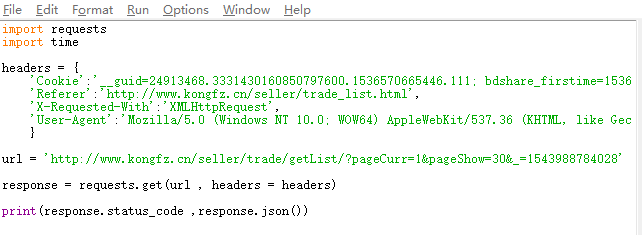

request后json的值为空,这是什么情况,各位老师给看看,谢谢
还有怎么上传图啊,手机。
 分享
分享
因为网站做了反爬,直接输入你的URL在浏览器就是空值
www.kongfz.cn/seller/trade/getlist/?pgeCurr=1&pageShow=30&_=1543988784028
可以尝试使用下requests.session()来传递cookie
分享




