

大佬们好,
小弟初来乍到,是个半出家的代码新手,还请多多包涵。
我想通过requests库爬取网站https://ecp.sgcc.com.cn/ecp2.0/portal/#/list/list-spe/2018032600289606_1_2018032700291334,获得相关的标题和链接。通过观察源代码,发现内容是以json格式储存的,初步写出来代码如下。
import requests
url = 'https://ecp.sgcc.com.cn/ecp2.0/ecpwcmcore//index/noteList'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
'referer': 'https://ecp.sgcc.com.cn/ecp2.0/portal/',
}
# request payload
payload = {
'index': '1'
}
#解析数据
res = requests.post(url,headers=headers,data=payload)
print(res.status_code)
print(res.url)
print(res.text)
note_list_json = res.json()
note_list = note_list_json['resultValue']['noteList']
print(type(note_list)) #<class 'list'>
#提取数据
for i in note_list:
#标题 title
title = i['title']
print(title)
#发布日期 noticePublishTime
pub_date = i['noticePublishTime']
print(pub_date)
#文件类型 doctype (用于拼接链接)
doc_type = i['doctype']
#编码 id (用于拼接链接)
doc_id = i['id']
#拼接链接
link = 'https://ecp.sgcc.com.cn/ecp2.0/portal/#/doc/' + doc_type + '/' + doc_id + '_2018032700291334'
print(link)
print('------------------------------')
终端报错结果如下:

回头看一下XHR,发现正常带有数据的内容不一样:报错的是{successful: false},正常的是{successful: true}。
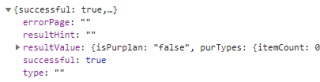
到这里就卡住了,因为不知道如何成功的获取数据推进到下一步。
如解决问题会私信您VX/ZFB转30元以表心意。希望能够得到帮助,谢谢!





