Python能不能实现像Origin中的那样分峰和多峰高斯拟合?
如图,需要提取各个小的峰
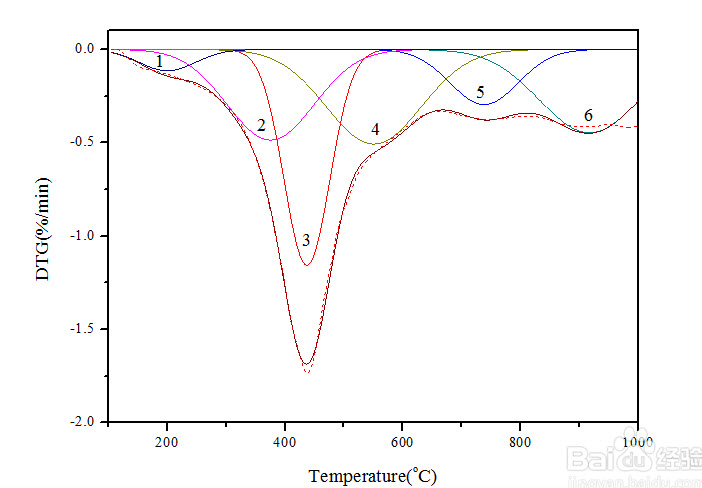

Python能不能实现像Origin中的那样分峰和多峰高斯拟合?
如图,需要提取各个小的峰
 分享
分享
以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
可以使用numpy库中的scipy模块来实现这样的功能。以下是一个简单的例子:
import numpy as np
from scipy.optimize import curve_fit
def gaussian(x, A, mu, sigma):
return A * np.exp(-(x - mu)**2 / (2 * sigma**2))
# 假设你的数据已经保存在list中,例如data = [0.0, 5, 6, ..., 1000]
data = [0.0] + list(np.arange(5, 21, 0.5)) + [1000]
# 计算每个点处的积分
intensities = np.trapz(data)
# 使用最小二乘法进行拟合
popt, pcov = curve_fit(gaussian, data, intensities)
print(popt)
这段代码首先定义了一个gaussian函数,然后计算了每个点的积分(因为高斯分布的积分等于它的面积),并将这些值作为输入给curve_fit函数。这个函数会尝试找到一个最优的参数组合(A, mu, sigma)来拟合这些数据。
注意:这个例子是基于原始数据的,如果你的数据不是这个格式,你可能需要对它做一些额外的处理。此外,这个方法只适用于单峰的情况,如果数据有多个峰,你需要将数据分成两部分,并分别求解。
分享

