
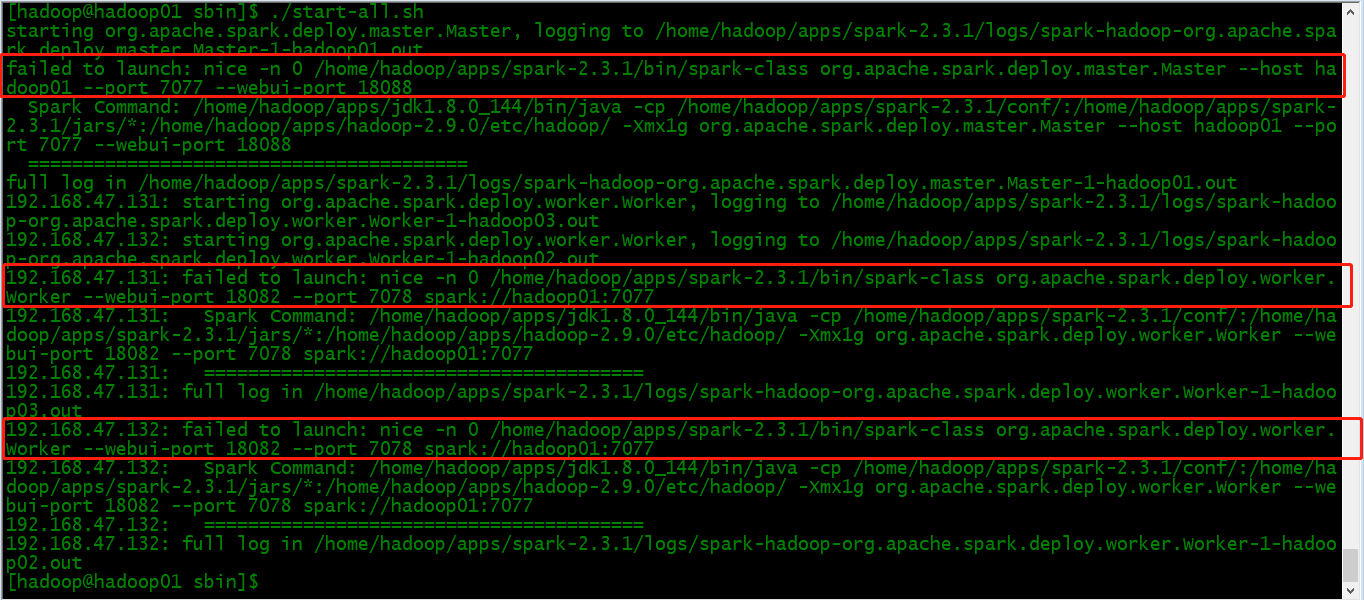


1条回答 默认 最新
 你知我知皆知 2024-08-07 15:17关注
你知我知皆知 2024-08-07 15:17关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
从您提供的日志来看,似乎Spark在尝试启动时遇到了一些问题。这可能是因为Spark环境配置错误、硬件资源不足或者是Spark版本不兼容等原因导致的。
以下是一些建议和步骤来解决这个问题:
步骤 1: 检查Spark环境配置
确保您的Spark环境配置正确且最新。如果您使用的是Hadoop集群,可以检查以下几点:
- 确保Hadoop版本与Spark版本兼容。
- 检查HDFS路径设置是否正确(例如:如果使用了Zookeeper作为分布式文件系统)。
- 确保JDK版本与Spark版本兼容。
- 确保所有依赖库都已正确安装并添加到类路径中。
步骤 2: 检查硬件资源
- 确保Hadoop集群有足够的可用内存和CPU资源。
- 如果是虚拟机环境,请确认虚拟机的硬件配置满足Spark运行的需求。
步骤 3: 检查Spark版本
- 确认使用的Spark版本是您期望的版本,并且已经更新到了最新状态。
- 如果您正在使用Apache Spark,确保其依赖包已更新到最新版本。
步骤 4: 检查Spark服务端口
- 确保Spark服务端口没有被其他程序占用。
- 如果Spark服务是通过网络访问的,确保网络连接正常并且防火墙允许访问这些端口。
步骤 5: 检查Spark主进程
- 检查Spark主进程的日志是否有任何错误消息或警告。
- 在控制台输出Spark的详细日志以获取更多关于失败原因的信息。
步骤 6: 重启Spark服务
- 使用
./start-slave.sh命令重新启动Spark服务。 - 如果问题仍然存在,您可以考虑使用Spark的诊断工具进行更深入的调试。
步骤 7: 查看Spark堆栈跟踪
- 打开终端,输入
jstack或者jmap命令查看Spark的堆栈跟踪。 - 这将帮助您了解Spark在启动过程中遇到的具体错误。
希望以上建议能帮到您解决问题!如果问题仍未得到解决,请提供更多的日志细节以便进一步分析。
解决 无用评论 打赏举报 分享
分享
- 2024-07-29 09:36bug菌¹的博客 如果以上步骤都无法解决问题,您可以提供具体的错误信息或异常堆栈,这将有助于进一步诊断问题。 以下是一个使用 PySpark 连接数据库的基本示例代码: from pyspark.sql import SparkSession # 创建 Spark session ...
- 2025-05-07 12:15面朝大海,春不暖,花不开的博客 Apache Spark 是一个分布式计算框架,适用于单机或集群环境。它通过内存计算和优化执行图显著提高了数据处理速度。...在本文中,我们将使用 Dataset API 处理文本数据,展示 Spark 在日志分析中的应用。
- 2024-09-03 08:45bug菌¹的博客 Spark 客户端创建失败 错误信息中提到了 Failed to create Spark client for Spark session,这通常表明 Hive 无法为执行任务创建 Spark 客户端。这可能是由于配置问题或环境问题导致的。 解决方案: 确保 Spark 和...
- 2025-06-14 12:04skywalk8163的博客 摘要:InfiniSynapse在Windows的Docker和Ubuntu环境(VirtualBox)中运行时频繁出现Unexpected end of JSON input错误,表现为服务短暂可用后...建议通过协议改进(如二进制传输)、资源监控及压力测试定位根本原因。
- 2026-01-04 14:46霍格沃兹测试开发学社-小明的博客 2026年AI日志自动归因技术已从概念验证走向工程落地,成为提升故障修复效率的核心工具。主流开源工具如Coroot、LogBERT等支持多模态分析、中文语义解析和CI/CD集成,准确率达85%以上。核心技术包括日志解析、语义...
- 2021-02-27 19:05
 Spark-rapids报错定位:Could not load cudf jni library... | ai.rapids.cudf.NativeDepsLoader.loadNativeDepszachonee的博客 @[TOC](Spark-rapids报错定位:Could not load cudf jni library… | ai.rapids.cudf.NativeDepsLoader.loadNativeDeps(NativeDepsLoader.java:91)java.io.IOException: Error loading dependencies) spark-shell提交...
Spark-rapids报错定位:Could not load cudf jni library... | ai.rapids.cudf.NativeDepsLoader.loadNativeDepszachonee的博客 @[TOC](Spark-rapids报错定位:Could not load cudf jni library… | ai.rapids.cudf.NativeDepsLoader.loadNativeDeps(NativeDepsLoader.java:91)java.io.IOException: Error loading dependencies) spark-shell提交... - 2017-03-30 16:24李孟聊人工智能的博客 1.自从spark2.0.0发布没有assembly的包了,在jars里面,是很多小jar包 修改目录查找jar 2.异常HiveConf of name hive.enable.spark.execution.engine does not exist 在hive-site.xml中: hive.enable....
- 2025-09-19 11:15黑客影儿的博客 本文介绍了Apache Spark MLlib机器学习库的完整使用流程,包括下载安装、基础配置、调试运行、运维管理和安全配置。主要内容涵盖:1)如何下载安装基于Spark生态的MLlib;2)核心配置文件参数说明;3)Python示例...
- 2023-06-06 15:41Samooyou的博客 spark
- 2018-07-11 09:22董可伦的博客 记录spark-submit提交Spark程序出现的一个异常,以供第一次出现这种异常且不知道原因,该怎么解决的的同学参考。
- 没有解决我的问题, 去提问