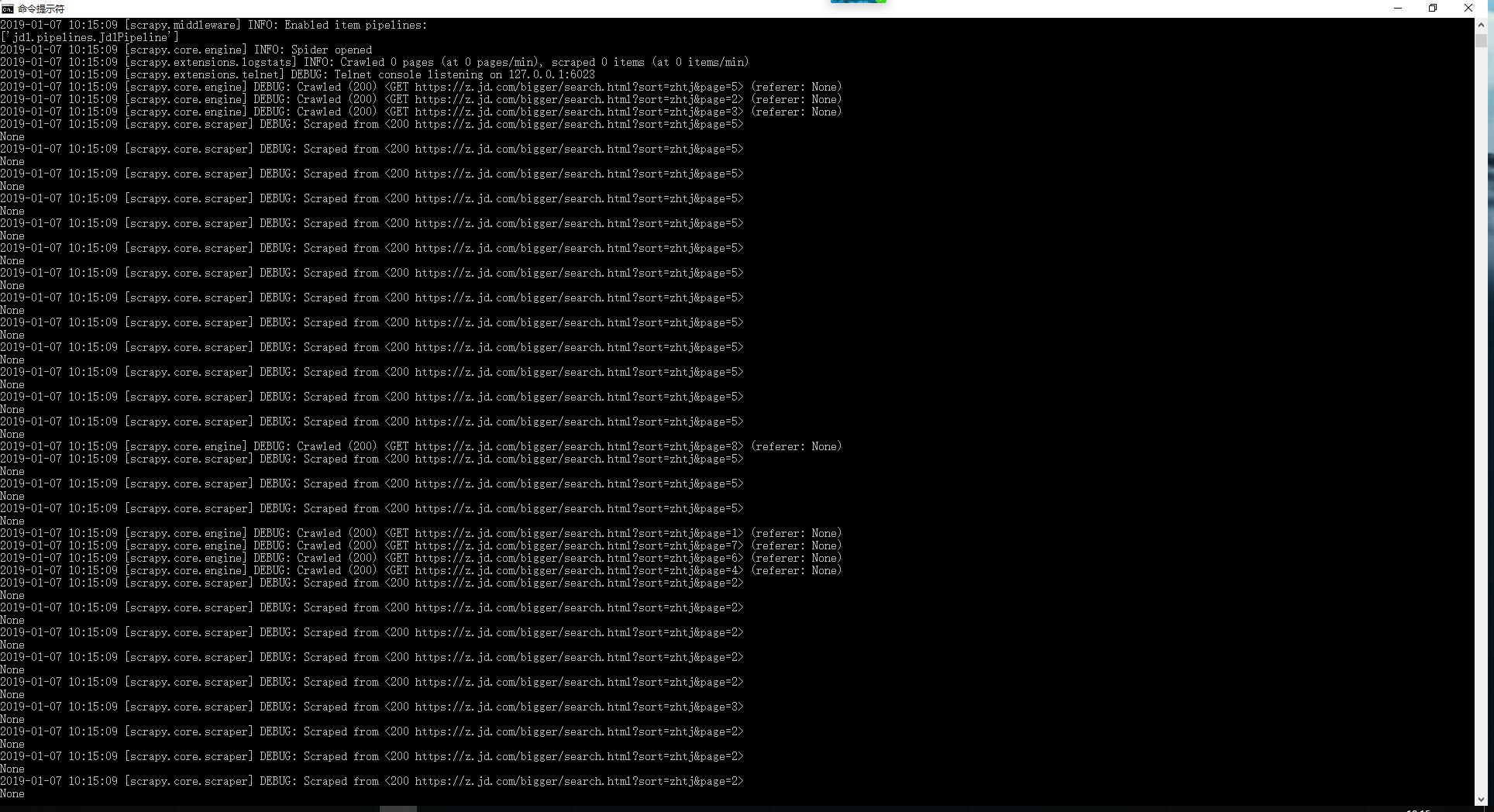
学习爬京东众筹前50页热卖商品信息,可以翻页,但不按顺序翻页,乱跳,请问是哪里出现问题了呢
import scrapy
# 导入items类, 使items类生效
from jd1.items import Jd1Item
import time
class Jdzch1Spider(scrapy.Spider):
name = 'jdzch1'
start_urls = ['https://z.jd.com/bigger/search.html?sort=zhtj&page=1']
def parse(self, response):
result = response.xpath('//li[@class="info type_now"]')
# 循环每个商品,提取所需信息
for i in result:
# 定义 item 字典
item = Jd1Item()
# 筛选信息
item['title'] = i.xpath('.//h4[@class="link-tit"]/text()').extract_first()
item['perc'] = i.xpath('.//li[@class="fore1"]/p[@class="p-percent"]/text()').extract_first()
item['outc1'] = i.xpath('.//li[@class="fore1"]/p[@class="p-extra"]/text()').extract_first()
item['money'] = i.xpath('.//li[@class="fore2"]/p[@class="p-percent"]/text()').extract_first()
item['outc2'] = i.xpath('.//li[@class="fore2"]/p[@class="p-extra"]/text()').extract_first()
item['time'] = i.xpath('.//li[@class="fore3"]/p[@class="p-percent"]/text()').extract_first()
item['outc3'] = i.xpath('.//li[@class="fore3"]/p[@class="p-extra"]/text()').extract_first()
yield item
time.sleep(3)
def start_requests(self):
j = 1
for j in range(5,0)[::-1]:
newurl = "https://z.jd.com/bigger/search.html?sort=zhtj&page=%d" % (j)
yield scrapy.Request(newurl, callback=self.parse)