@src提不出来 同一个标签下的其他属性都行 希望大神能帮忙解答一下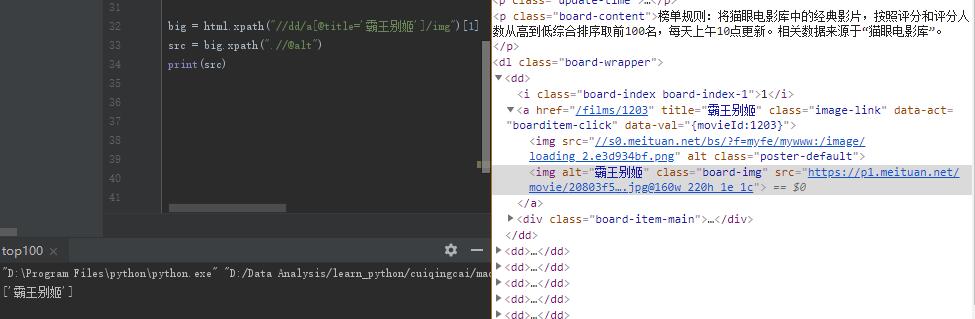
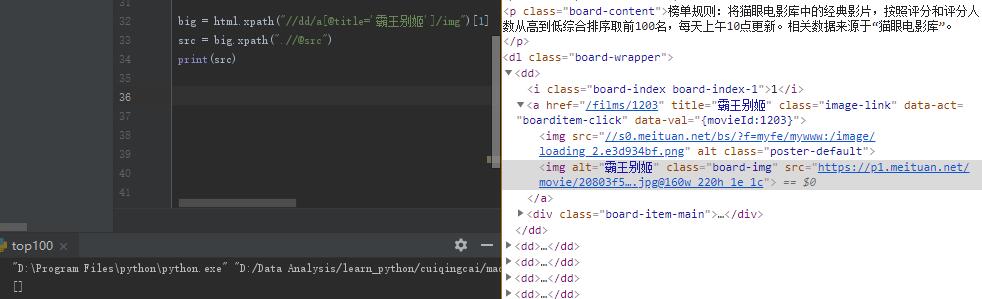

python爬虫 @src 为什么不能提取到图片网址

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


5条回答 默认 最新

- 2022-01-27 12:25回答 4 已采纳 图片是js解析出来的,xpath无效,数据在js变量里面,正则提取下数据用json.loads加载获取 代码如下 import requests import re import json def
- 2021-12-18 11:16回答 2 已采纳 题主要的代码如下, from bs4 import BeautifulSoup import requests header = {"user-agent":"Mozilla/5.0.html (
- 2021-05-22 21:34回答 1 已采纳 这里我们以爬取淘宝评论为例子讲解一下如何去做到的。 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析js
- 2021-12-28 15:41Reader_a的博客 Python爬虫爬取图片 需要用到的库: os time request lxml 代码源码如下: import os import time import requests from lxml import etree #建议headers写全 也可以只写user-agent和cookie headers = { 'User-Agent...
- 2022-05-30 23:15回答 2 已采纳 不知道是不是有个逗号的原因,然后把后面给截断了,可以试试正则去提取 import requests,re url = 'https://www.renren.com/login' rep=reque
- 2022-03-12 18:24回答 2 已采纳 题主获取的是style属性,不是src啊。。@style改为@src而且少了body,etree会自动补全body html中缺少的话,示例如下。。 from lxml import etree s=
- 2022-11-22 18:05回答 2 已采纳 import requests import re import os if __name__ == '__main__': if not os.path.exists('./nbaLibs'
- 2023-08-19 00:10在这个Python爬虫案例中,我们首先导入了所需的库,然后定义了三个函数:get_html()用于获取网页内容,get_img_links()用于解析HTML并提取图片链接,save_imgs()用于保存图片。 在get_html()函数中,我们使用...
- 2021-03-27 16:46回答 1 已采纳 将原代码中这段内容: for j in page_spec_data: for k in j.a: # print(k.string) value_word
- 2021-03-07 11:27回答 3 已采纳 数据是js动态渲染的,scrapy需结合splash使用,用selenium速度虽慢点,但是对js加载数据的获取准确性较高。 driver.implicitly_wait(5) #page=dri
- 2020-12-25 10:40回答 3 已采纳 res = requests.post(url,headers=headers,json=payload)
- 2017-11-28 22:51简单的爬虫入门,可以改变代码里的节点 爬虫类似的图片网站
- 2021-03-07 15:54回答 2 已采纳 两个方法一个 是找到后端接口,直接请求后端接口 另一个是操作selenium点击加载
- 2020-12-10 08:35weixin_39941620的博客 那么有没有什么方法可以用python爬虫在知乎上只提取图片呢?下面的代码注释请仔细阅读,中间有一个小BUG,需要手动把pic3修改为pic2这个地方目前原因不明确,可能是我本地网络的原因,还有请在项目...
- 2023-08-19 00:08对于每个标签,我们检查它是否有src属性,如果有,我们就认为这个标签是一个图片或视频的URL。我们将所有找到的图片和视频的URL保存在一个列表中,并返回这个列表。 3. 接下来,我们定义了一个download_img_and_...
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 如何处理复杂数据表格的除法运算
- ¥15 如何用stc8h1k08的片子做485数据透传的功能?(关键词-串口)
- ¥15 有兄弟姐妹会用word插图功能制作类似citespace的图片吗?
- ¥200 uniapp长期运行卡死问题解决
- ¥15 请教:如何用postman调用本地虚拟机区块链接上的合约?
- ¥15 为什么使用javacv转封装rtsp为rtmp时出现如下问题:[h264 @ 000000004faf7500]no frame?
- ¥15 乘性高斯噪声在深度学习网络中的应用
- ¥15 关于docker部署flink集成hadoop的yarn,请教个问题 flink启动yarn-session.sh连不上hadoop,这个整了好几天一直不行,求帮忙看一下怎么解决
- ¥15 深度学习根据CNN网络模型,搭建BP模型并训练MNIST数据集
- ¥15 C++ 头文件/宏冲突问题解决