
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
}
url = '
'
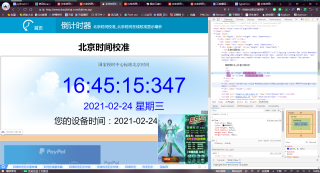
#获取当前时间
res = requests.get(url,headers=headers)
time = BeautifulSoup(res.text,'lxml')
bjtime = time.find_all('div')
print(bjtime[7].text)





