

做包含中英文的txt的词云。
开始是出不来图,词云图的黑色背景中显示类似这样一行<0x00000021FA66>的乱码

我以为是字体问题,就找到wordcloud,用simhei.ttf替换了自带的DroidSansMono.ttf,同时修改了.py文件
但是还是没有变化,黑色背景图里还是上面那个样子
于是开始逐个排查发现2个问题:
1.
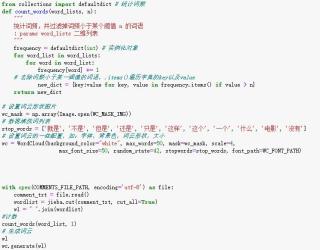
word_list无法打印出东西,print()也不行。(见下图)

后来百度看别人代码发现加上 wl = " ".join(wordlist) 可以解决问题,但是不知道什么原理
2.继续排查发现KeyError问题,但是我代码里好像没用字典,不知道是否是跟内置函数有冲突
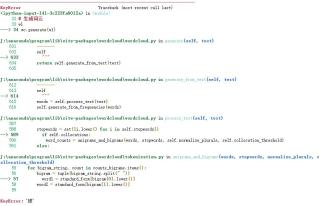

于是我就去.py找到了57行这个bigram,发现是一个分词函数但是我不知道这行代码是什么意思,他运行到第一个字“被”,就出现问题了,我该如何修改才能生成正确词频词云图?谢谢!
最后附一下全的代码:
import os
import re
import time
import random
import requests
import jieba
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 生成Session对象,用于保存Cookie
s = requests.Session()
# 词云形状图片
WC_MASK_IMG = 'K:/test.jpg'
# 影评数据保存文件
COMMENTS_FILE_PATH = 'K:/douban_comments.txt'
# 词云字体
WC_FONT_PATH = '/Library/Fonts/Songti.ttc'
# 统计词频
from collections import defaultdict
def login_douban():
"""
登录豆瓣
:return:
"""
# 登录URL
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
# 请求头
headers = {'user-agent': 'Mozilla/5.0', 'Referer': 'https://accounts.douban.com/passport/login?source=main'}
# 传递用户名和密码
data = {'name': '你的账号',
'password': '你的密码',
'remember': 'false'}
try:
r = s.post(login_url, headers=headers, data=data)
r.raise_for_status()
except:
print('登录请求失败')
return 0
# 打印请求结果
print(r.text)
return 1
def spider_comment(page=0):
"""
爬取某页影评
:param page: 分页参数
:return:
"""
print('开始爬取第%d页' % int(page))
start = int(page * 20)
comment_url = 'https://movie.douban.com/subject/3011091/comments?start=%d&limit=20&sort=new_score&status=P' % start
# 请求头
headers = {'user-agent': 'Mozilla/5.0'}
try:
r = s.get(comment_url, headers=headers)
r.raise_for_status()
except:
print('第%d页爬取请求失败' % page)
return 0
# 使用正则提取影评内容
comments = re.findall('<span class="short">(.*)</span>', r.text)
if not comments:
return 0
# 写入文件
with open(COMMENTS_FILE_PATH, 'a+', encoding='utf-8') as file:
file.writelines('\n'.join(comments))
return 1
def batch_spider_comment():
"""
批量爬取豆瓣影评
:return:
"""
# 写入数据前先清空之前的数据
if os.path.exists(COMMENTS_FILE_PATH):
os.remove(COMMENTS_FILE_PATH)
page = 0
while spider_comment(page):
page += 1
# 模拟用户浏览,设置一个爬虫间隔,防止ip被封
time.sleep(random.random() * 3)
print('爬取完毕')
def cut_word():
"""
对数据分词
:return: 分词后的数据
"""
with open(COMMENTS_FILE_PATH, encoding='utf-8') as file:
comment_txt = file.read()
wordlist = jieba.cut(comment_txt, cut_all=True)
wl = " ".join(wordlist)
print(wl)
return wl
def create_word_cloud():
"""
生成词云
:return:
"""
# 设置词云形状图片
wc_mask = np.array(Image.open(WC_MASK_IMG))
# 数据清洗词列表
stop_words = ['就是', '不是', '但是', '还是', '只是', '这样', '这个', '一个', '什么', '电影', '没有']
# 设置词云的一些配置,如:字体,背景色,词云形状,大小
wc = WordCloud(background_color="white", max_words=50, mask=wc_mask, scale=4,
max_font_size=50, random_state=42, stopwords=stop_words, font_path=WC_FONT_PATH)
# 生成词云
wc.generate(cut_word())
# 在只设置mask的情况下,你将会得到一个拥有图片形状的词云
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.figure()
plt.show()
if __name__ == '__main__':
# 登录成功才爬取
# if login_douban():
# # spider_comment(30)
batch_spider_comment()
create_word_cloud()




