import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
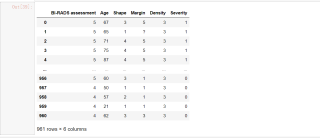
df =pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/mammographic-masses/mammographic_masses.data', sep=',',header=None)
df.columns = ['BI-RADS assessment','Age','Shape','Margin','Density','Severity']
b= df.sort_values(by='Severity',ascending=False)
b.index = range(len(b))
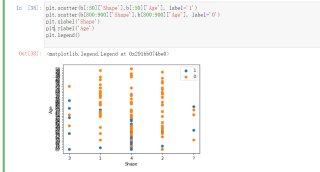
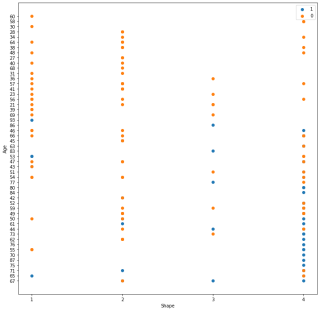
plt.scatter(b[:50]['Shape'],b[:50]['Age'], label='1')
plt.scatter(b[800:900]['Shape'],b[800:900]['Age'], label='0')
plt.xlabel('Shape')
plt.ylabel('Age')
plt.legend()
我是python初学者,
上面的代码是通过鸢尾花代码改过来的,想用UCI上的其他的库,但是输出的散点图x,y轴一直是乱序的
非常感谢大佬能够提供一些帮助,谢谢!!!
如下图: