mysql中有一个表将近六百万数据有两个重复的,如何可以高效的把这两个重复的找出来并删除啊?



2条回答 默认 最新
 ll89308839 2012-03-28 19:27关注
ll89308839 2012-03-28 19:27关注[code="java"]
select rowname from tableName group by rowname
having count(rowname ) > 1
[/code]本回答被题主选为最佳回答 , 对您是否有帮助呢?解决评论 打赏无用 1举报 分享
分享
- 2012-03-28 10:27回答 2 已采纳 [code="java"] select rowname from tableName group by rowname having count(rowname ) > 1 [/co
- 2022-03-31 17:24回答 5 已采纳 其实没有实际的标准明确定义多少数据量算大数据,不过阿里开发手册中建议,表数据超过500万条时,建议考虑分表,以防影响查询效率,不过我们公司也有单表超过几千万条的数据,效率确实不高,所以理论上百万级别以
- 2021-09-18 10:38回答 4 已采纳 你好像描述的有些问题吧?为什么查询大数据展示?你口中的大数据指定到底是什么?如果你是学习大数据(hadoop相关),使用java语言在做数仓项目,那么你可以参考一下这张图 查询数据一般从数据库里面查
- 2019-11-24 21:48乔治大哥的博客 MySQL由于自身简单、高效、可靠的特点,成为小米内部使用最广泛的数据库,但是当数据量达到千万/亿级别的时候,MySQL的相关操作会变的非常迟缓;如果这时还有实时BI展示的需求,对于mysql来说是一种灾难。 为了解决...
- 2017-06-01 07:11回答 3 已采纳 查询语句最好不要直接写select * from table,用具体的字段列表代替“*”,不要返回用不到的任何字段,这样能提高语句的效率; 另外,40万数据用了1.29秒,而且语句中包含group
- 2018-05-14 14:01回答 19 已采纳 如是普通PC级服务器(或是更好一点的消费级服务器),你每条数据平均占用时间为40MS,考虑到你的每条数据有900多列。这样的话,已经不慢了。 如想更快的话: 1、查看是否有索引,索引是以降低插
- 2017-05-18 01:06回答 6 已采纳 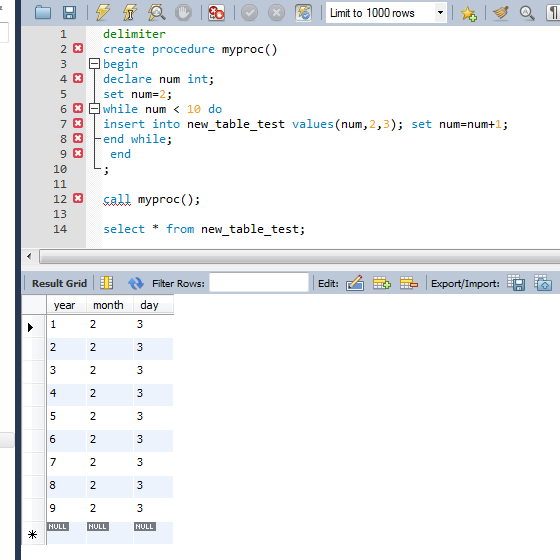 delimiter create proce
- 2023-04-26 16:26约定Da于配置的博客 本题来源于全国职业技能大赛之大数据技术赛项电商赛题-离线数据处理-抽取什么是全量数据、增量数据?1.全量数据:当前需要迁移的数据库系统的全部数据。2.增量数据:在数据库系统迁移过程中,对比原数据,新产生的...
- 2023-04-02 16:21回答 4 已采纳 先用select查一波,确定这个编号有数据,再update
- 2022-10-12 21:51回答 1 已采纳 解决了,没有开启checkpoint导致,加上下面代码即可env.enableCheckpointing(1000, CheckpointingMode.EXACTLY_ONCE);env.getCh
- 2022-12-07 17:18回答 4 已采纳 使用 instr函数试试看 ,查询 like '%121%' select * from test t where instr(t.requestdata,'121')> 0;
- 2021-05-13 16:06黄杏波的博客 首先,我们进入information_schema 库 use information_schema; 查看指定库下各个表的大小,我这里按照表数据行数降序排列 ...这个是查询结果,这些数据量达到200万的就过滤掉了 最后在mysql部署机器..
- 2022-03-02 16:48回答 1 已采纳 一般这种工具都会提供自定义sql执行的,比如 const results = yield app.mysql.query('update posts set status = 1 where id i
- 2021-01-19 23:13除了oracle数据库模型移到mysql外,还一个重要环节就是要将oracle数据库的数据移到mysql数据库,本人尝试用过多款数据迁移程序,性能都不是很好的,于是自己动手写一个针对于oracle数据库数据迁移到mysql数据程序,...
- 2022-01-14 20:25嗯嗲和滴的博客 大数据的数据同步主要包括从分布式业务系统同步进入数据仓库和数据从数据仓库同步进入数据应用和数据服务两个方面。本文主要讲述的是前者。 从业务系统同步数据到数据仓库的数据同步总的说来分为三种,直连同步...
- 没有解决我的问题, 去提问


