
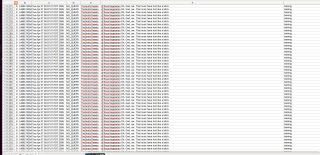
如题,最近在弄联邦学习,需要针对csv数据文件进行处理,其csv数据结构如图所示

其中F列被我手动插入了....well七个不相关字符作为的语句结尾,并且最前面一列的数值也被改成了10(原先是0,也部分数值为2),我现在想通过对第F列即文本这一列进行结尾匹配。在匹配到结尾是“...well”的同时,其第一列的数值还等于10的情况下,将这一行删除,最终形成新的csv文件。
自己曾尝试过单纯的检索"...well"这一语句结尾,以下代码参考自https://cloud.tencent.com/developer/ask/133635以及https://www.cnpython.com/qa/130739
with open('all_data.csv', 'r') as fin, open('all_data_2.csv', 'w', newline='') as fout:
# define reader and writer objects
reader = csv.reader(fin, skipinitialspace=True)
writer = csv.writer(fout, delimiter=',')
for row in reader:
for line in row [5]:
if str(line[-5:]) != '..well':
writer.writerow(row)
但结果不甚理想,最终出来的文件由于两次for出现了数据的重复,在运行脚本的时候,运行时间也大幅延长了。
总感觉临门一脚了,但总是不成功
根据答案提供的参考思路,我用了以下代码,但是输出的结果好像有点问题,我算是最近才接触python,很多基础都不牢固
df = pd.read_csv('all_data.csv',header = None)
data = df[~((df[0]==10)&(df[5].str[-5:]=='..well'))]
data.to_csv("all_data_2.csv")
这个的结果输出出来后是原本的文件都没有改,完完整整输出出来了,而且我说的A列和F列只是代称,那个列名是csv自带的,所以用了None的head来进行读取,但是结果出来如下图

由于我没有加index = None,所以多了一列,这个我晓得如何处理,但是现在问题是原本的数据好像没有改变,应该是我筛选的那段有问题,希望答案能更具体一些,因为我算是小白,有蛮多都还不太懂,很多代码都是搜索后按照步骤来写的





