

!pip install selenium
import csv
import codecs
from selenium import webdriver
import time
import pandas as pd
import copy
browser = webdriver.Chrome(executable_path = './chromedriver')
page_url = "https://so.eastmoney.com/web/s?keyword="
browser.get(page_url)
time.sleep(3)
search = browser.find_element_by_xpath('//input[@id="search_key"]')
search.send_keys("字节跳动")
browser.find_element_by_xpath('//input[@type="submit"]').click()
time.sleep(3)
news_urls = []
news_list1 = browser.find_elements_by_xpath('//div[@class="news_item_url"]')
for nl in news_list1:##coding: utf-8
url = nl.find_element_by_xpath('.//a').get_attribute('href')
time.sleep(3)
news_urls.append(url)
for idx in range(2,25):
browser.find_element_by_xpath('//a[@title="下一页"]').click()
time.sleep(4)
print("第", idx, "页:")
news_list1 = browser.find_elements_by_xpath('//div[@class="news_item_t"]')
for nl in news_list1:##coding: utf-8
url = nl.find_element_by_xpath('.//a').get_attribute('href')
news_urls.append(url)
alist=['新闻url','新闻标题','发布时间','发布来源','访问人数','评论人数','新闻内容']
blist=[]
clist=[]
for url in news_urls:
browser.get(url)
time.sleep(3)
print(url)
blist.append(url)
title = browser.find_element_by_xpath('//*[@id="topbox"]/div[1]') #####改动
blist.append(title.text)
release = browser.find_element_by_xpath('//*[@id="topbox"]/div[3]/div[1]/div[1]') #####改动
blist.append(release.text)
try:
source1 = browser.find_element_by_xpath('//*[@id="topbox"]/div[3]/div[1]/div[3]') #####改动
blist.append(source1.text)
except:
source2 = browser.find_element_by_xpath('//*[@id="topbox"]/div[3]/div[1]/div[2]') #####改动
blist.append(source2.text)
try:
visit_num = browser.find_element_by_xpath('//*[@id="gopinluntxt1"]/div[2]/span') #####改动
comment_num=browser.find_element_by_xpath('//*[@id="gopinluntxt1"]/div[1]/span')
blist.append(visit_num.text)
blist.append(comment_num.text)
except:
visit_num = browser.find_element_by_xpath('//*[@id="gopinluntxt1"]/div/span') #####改动
comment_num='未显示'
blist.append(visit_num.text)
blist.append(comment_num)
content = browser.find_element_by_xpath('//*[@id="ContentBody"]') #####改动
blist.append(content.text)
clist.append(blist)
blist=[]
with open('字节跳动修改版.csv','w',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
csv_write.writerow(alist)
for item in clist:
csv_write.writerow(item)
browser.close()
初写爬虫 总是这个地方报错 (有的时候会报错xpath好像定位不太行) 能否纠正完善一下
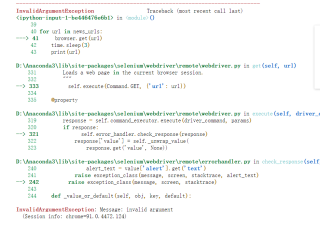
在原来的代码的基础上,在for url in news_urls:后面,加了一个try except语句,发现代码可以跑完,但在表格里发现有一行多了一个url 能请解释一下吗
for url in news_urls:
try:
print(url)
browser.get(url)
time.sleep(3)
blist.append(url)
title = browser.find_element_by_xpath('//*[@id="topbox"]/div[1]') #####改动
blist.append(title.text)
release = browser.find_element_by_xpath('//*[@id="topbox"]/div[3]/div[1]/div[1]') #####改动
blist.append(release.text)
try:
source1 = browser.find_element_by_xpath('//*[@id="topbox"]/div[3]/div[1]/div[3]') #####改动
blist.append(source1.text)
except:
source2 = browser.find_element_by_xpath('//*[@id="topbox"]/div[3]/div[1]/div[2]') #####改动
blist.append(source2.text)
try:
visit_num = browser.find_element_by_xpath('//*[@id="gopinluntxt1"]/div[2]/span') #####改动
comment_num=browser.find_element_by_xpath('//*[@id="gopinluntxt1"]/div[1]/span')
blist.append(visit_num.text)
blist.append(comment_num.text)
except:
visit_num = browser.find_element_by_xpath('//*[@id="gopinluntxt1"]/div/span') #####改动
comment_num='未显示'
blist.append(visit_num.text)
blist.append(comment_num)
content = browser.find_element_by_xpath('//*[@id="ContentBody"]') #####改动
blist.append(content.text)
clist.append(blist)
blist=[]
except:
continue
####这样加了try except 会不会有点不严谨 有的都没有跑到

加了一个整体的try except 发现表格里有一行多了一个url 为啥呢







