
import urllib.parse
import urllib.request
def requert_get(page):
first_url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data={
'start':(page-1)*20, #根据上面规则start = (page-)*20. 所以我们需要实参page的值
'limit':20
}
data=urllib.parse.urlencode(data)
url= first_url+data
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
requerst=urllib.request.Request(url=url,headers=headers)
return requerst
def reqopne_get(requerst):
content = urllib.request.urlopen(requerst) #模拟浏览器像服务器发送请求
contents=content.read().decode('utf-8')
return contents #返回contents的值
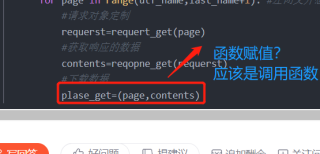
def plase_get(page,contents):
with open('douban.'+str(page)+'json','w',encodings='utf-8') as fp:
fp.write(contents)
if __name__ == '__main__':
utf_name=int(input('请输入开始页码'))
last_name=int(input('请输入结束页码'))
for page in range(utf_name,last_name+1): #左闭又开想要获取10页数据 10+1 11获取第10页数据
#请求对象定制
requerst=requert_get(page)
#获取响应的数据
contents=reqopne_get(requerst)
#下载数据
plase_get=(page,contents)

基础爬虫 不报错也不下数据

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

4条回答 默认 最新

 关注
关注帮你改好了
```python import urllib.parse import urllib.request def requert_get(page): first_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&' data = { 'start': (page - 1) * 20, # 根据上面规则start = (page-)*20. 所以我们需要实参page的值 'limit': 20 } data = urllib.parse.urlencode(data) url = first_url + data headers = { 'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49' } requerst = urllib.request.Request(url=url, headers=headers) return requerst def reqopne_get(requerst): content = urllib.request.urlopen(requerst) # 模拟浏览器像服务器发送请求 contents = content.read().decode('utf-8') return contents # 返回contents的值 def plase_get(page, contents): filename = 'douban.' + str(page) + 'json' with open(filename, 'w', encoding='utf-8') as fp: fp.write(contents) print('保存完成') if __name__ == '__main__': utf_name = int(input('请输入开始页码')) last_name = int(input('请输入结束页码')) for page in range(utf_name, last_name + 1): # 左闭又开想要获取10页数据 10+1 11获取第10页数据 # 请求对象定制 requerst = requert_get(page) # 获取响应的数据 contents = reqopne_get(requerst) # 下载数据 plase_get(page, contents)```
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
- 2024-05-28 22:57m0_45207459的博客 刚学爬虫对着视频想爬个网络小说但是代码写完不报错也不出结果,大佬们帮忙看看啥情况。# 从元组中取出部分链接进行拼接,获取每章的页面链接。# XPATH筛选出文本数据,并将数据列表转换成字符串。print("正在下载" ...
- 2020-12-14 13:03weixin_39615643的博客 它也是搜索引擎的基础,像百度和GOOGLE都是凭借强大的网络爬虫,来检索海量的互联网信息的然后存储到云端,为网友提供优质的搜索服务的。二、爬虫有什么用你可能会说,除了做搜索引擎的公司,学爬虫有什么用呢?哈哈...
- 2021-12-26 19:31cortanaji的博客 #coding":"utf-8 import requests import hashlib import time import random import json class Youdao(object): def __...#解析数据 if __name__ == '_main_': youdao = Youdao("人生苦短,及时行乐") youdao.run()
- 2020-11-28 12:43weixin_39911998的博客 在入门爬虫的时候遇到不少问题,和不是唯一的解决方法的方法,总结整理一下,供大家学习交流。syntaxerror: invalid syntax语法错误:无效语法syntaxerror: unexpected EOF while parsing语法错误:多了无法解析的...
- 2024-09-15 11:49【作品名称】:基于python+selenium的51job网站爬虫与数据可视化分析 【适用人群】:适用于...不一定能够满足所有人的需求,需要有一定的基础能够看懂代码,能够自行调试代码并解决报错,能够自行添加功能修改代码。
- 2024-08-10 18:00二川bro的博客 Python运行不报错又无任何结果输出
- 2020-11-28 12:43weixin_39532352的博客 cannot find Chrome binary 在爬虫时经常会使用selenium实现自动化,来模拟Google访问目标网页,如果出现标题中错误,可能是你自定义目录安装了谷歌浏览器,谷歌的二进制可执行文件(一般文件名为chrome.exe)不在...
- 2024-11-05 14:27【作品名称】:基于 python 实现的Boss直聘岗位数据爬虫分析可视化 【适用人群】:适用于希望学习不同技术领域的小白或进阶学习者。可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【项目介绍】: ...
- 2022-10-22 07:00艾派森的博客 本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。
- 2023-06-08 21:44坚持不懈的大白的博客 最简单的爬虫代码 也就是各位最常使用的,直接利用requests模块访问当前网站链接,利用相关解析模块从而获取得到自己想要的数据,如下(利用python爬虫爬取自己csdn个人主页的简介数据): # -*- coding: utf-8 -*- ...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
7月24日
系统已结题
7月24日 已采纳回答
7月16日
已采纳回答
7月16日-
创建了问题
7月15日