音乐网站:http://www.dj024.com 爬取“现场串烧”列表下的每一个音乐下载地址。源码里面的下载地址是异步加载的。

可是怎么也获取不到json,访问如下地址获取的不是json,是html代码,设置“Content-Type: application/json”,用session都不行!
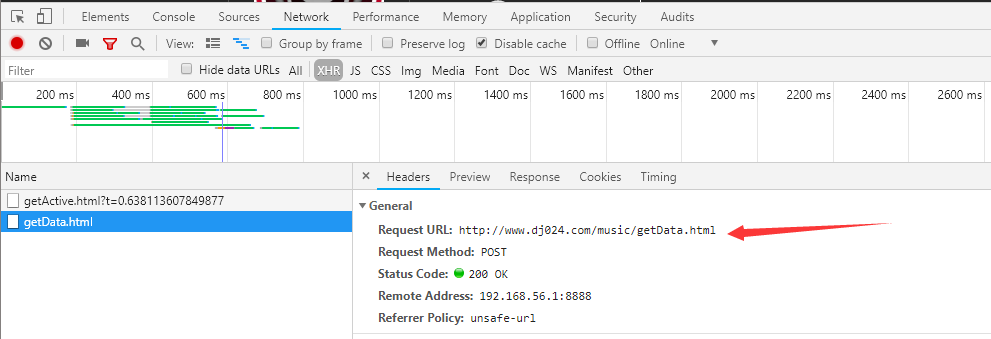
求大神指教,最好贴出代码。

音乐网站:http://www.dj024.com 爬取“现场串烧”列表下的每一个音乐下载地址。源码里面的下载地址是异步加载的。
可是怎么也获取不到json,访问如下地址获取的不是json,是html代码,设置“Content-Type: application/json”,用session都不行!
求大神指教,最好贴出代码。
 分享
分享
import requests
import json
url = 'http://www.dj024.com/music/getData.html'
headers = {'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Content-Length':'8',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'PHPSESSID=3msh15458cladsa4rs44blcqn6; Hm_lvt_5638419b16434ebb48ea2bdef1114b97=1548209089,1548209110; jy_home_user=think%3A%7B%22status%22%3A%221%22%2C%22data%22%3Anull%7D; jy_home_ListenRecord=think%3A%5B%2237393%22%2C%2237401%22%2C%2237348%22%5D; Hm_lpvt_5638419b16434ebb48ea2bdef1114b97=1548209462; jy_home___forward__=%2Fuser%2Faccount%2FgetActive.html%3Ft%3D0.5699561267137225',
'Host':'www.dj024.com',
'Origin':'http://www.dj024.com',
'Referer':'http://www.dj024.com/topics/37401.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'}
data = {'id':'37401'}
html = requests.post(url,headers = headers,data = data).content
print(html)
字段是listen_url,有转义符,用replace替换了就行
分享

